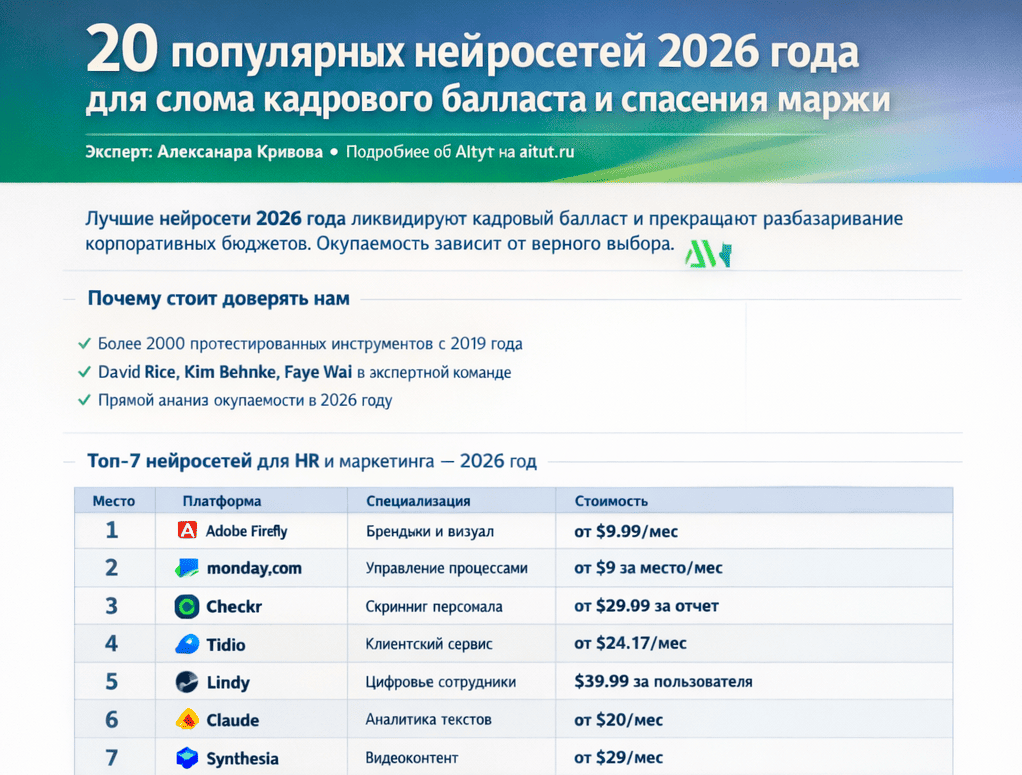
Чат GPT оказался в центре неприятного вопроса, который сегодня обсуждают инвесторы, разработчики и корпорации: можно ли удержать лидерство, когда китайские модели ИИ сокращают технологический разрыв до нескольких месяцев. Шок DeepSeek вскрыл реальную проблему рынка нейросетей — зависимость всей индустрии от вычислительной мощности, капитала и глобальной базы пользователей.
Впечатляющие модели искусственного интеллекта китайской лаборатории DeepSeek за один день обрушили акции американского разработчика микросхем Nvidia более чем на полтриллиона долларов. Это вдвое превысило предыдущий рекордный спад для отдельных акций на фоне общего обвала американского технологического сектора.
DeepSeek, дочерняя компания китайского хедж-фонда, подорвала уверенность в двух ключевых предположениях, лежащих в основе бума чат GPT:
-
Во-первых, что экспортный контроль США, ограничивающий доступ Китая к вычислительным мощностям, обеспечит американским AI-компаниям значительное и устойчивое преимущество.
-
Во-вторых, что растущий спрос на лучшие нейросети будет и дальше стимулировать устойчивый спрос на микросхемы для ИИ, центры обработки данных и электроэнергию. Год спустя первое предположение оказалось явно неверным, а второе в основном подтвердилось.
Уже второй год подряд начинается с сомнений относительно перспектив ChatGPT и американских лабораторий искусственного интеллекта, а также компаний, занимающихся облачными вычислениями. На этот раз опасения вызывают растущая задолженность, амортизация и циклическое финансирование поставщиков.
.png")
Шок от DeepSeek может помочь пролить свет на перспективы бума нейросетей
До января 2025 года лучшая модель DeepSeek соответствовала модели чат GPT-4 американской компании OpenAI, выпущенной годом и восемью месяцами ранее. Китай отставал в разработке моделей для обработки больших языков и столкнулся с американским экспортным контролем, который запрещал Nvidia продавать свои лучшие полупроводники для обучения нейросетей в Китай.
Но модель DeepSeek R1, выпущенная в январе 2025 года и обученная на оптимизированных чипах Nvidia, заявила о «производительности на одном уровне» с моделью чат GPT-o1 от OpenAI, выпущенной менее чем за два месяца до этого.
R1 превзошла модели американских компаний Anthropic, Google, Meta и xAI, которые, в отличие от DeepSeek, могли покупать передовые американские чипы, показав лучшие результаты по широко используемому индексу интеллекта.
Еще более шокирующим, хотя и не совсем убедительным, было утверждение DeepSeek о том, что ее модели были обучены с использованием вычислительной мощности стоимостью всего около 6 миллионов долларов. Она также была очень эффективной и дешевой: стоимость использования R1 была примерно в 27 раз ниже, чем у модели чат GPT-o1 от OpenAI.
Почему китайские нейросети догнали США
Модели DeepSeek были выпущены в «открытом виде», поэтому любой, у кого есть собственный облачный провайдер или мощные вычислительные мощности, мог загрузить и запустить их, потратив только средства на свои чипы и электроэнергию.
Выпуск DeepSeek, казалось, подорвал экономическую модель американских разработчиков ChatGPT, предоставив практически бесплатные и почти столь же качественные альтернативы. Джек Ма, как известно, сделал это с eBay, запустив Taobao в начале 2000-х, пошутив:
«У них огромные карманы, но мы проделаем в них дыру».
Китайская конкуренция, предлагающая «достаточно хорошие» продукты, могла привлечь потенциальных платящих клиентов американских ИИ-продуктов, лишив их доходов, необходимых для дальнейшей покупки чипов и электроэнергии. Перспектива обучения сложных моделей с минимальной вычислительной мощностью и повышением эффективности за счет снижения вычислительной мощности, необходимой для вывода (запуска моделей), предполагала, что все эти чипы и электроэнергия могут вообще не понадобиться, даже если американские лаборатории чат GPT смогут себе их позволить.
.png")
Технологические особенности последних моделей чат GPT и DeepSeek
Рынок генеративного ИИ фактически разделился на две инженерные школы. Первая — закрытые проприетарные системы вроде чат GPT от OpenAI, ориентированные на масштабируемую инфраструктуру и глобальные API-платформы. Вторая — архитектуры нового поколения, которые демонстрируют китайские лаборатории, включая DeepSeek, где основной акцент сделан на вычислительной эффективности и архитектуре Mixture-of-Experts.
Последние модели обеих линий — ChatGPT (серии GPT-4o / o1) и DeepSeek-R1 / V3 — используют разные инженерные подходы к решению одной задачи: масштабирования reasoning-моделей.
DeepSeek, например, применяет архитектуру Mixture-of-Experts (MoE) с 671 млрд параметров, но активирует лишь около 37 млрд параметров на токен, что резко снижает вычислительную нагрузку при инференсе.
OpenAI в моделях уровня чат GPT-o1 делает ставку на вычислительно тяжёлые reasoning-механизмы и сложные цепочки рассуждений, что повышает точность решений в сложных задачах.
При этом DeepSeek заявляет, что обучение их модели потребовало примерно 2,8 млн GPU-часов, что эквивалентно примерно 5–6 млн долларов вычислительных затрат, тогда как обучение моделей уровня GPT-4 оценивается в 50–100 млн долларов.
Таблица сравнения технологических параметров моделей
|
Параметр |
ChatGPT (GPT-4o / o1) |
DeepSeek-R1 / V3 |
|
Тип модели |
проприетарная foundation-модель |
частично открытая модель |
|
Архитектура |
Transformer + reasoning chain |
Mixture-of-Experts (MoE) |
|
Общее число параметров |
официально не раскрыто (оценки >1 трлн для некоторых версий) |
~671 млрд параметров |
|
Активные параметры на токен |
неизвестно |
~37 млрд |
|
Контекстное окно |
~128k токенов (GPT-4o) |
до ~128k токенов |
|
Скорость генерации |
~77 токенов/сек |
ниже при reasoning-режиме |
|
Стоимость API |
около $2.5 за млн входных токенов и $10 за млн выходных |
значительно дешевле на инференсе |
|
Основная специализация |
универсальный multimodal AI |
математическое и логическое reasoning |
|
Метод обучения |
SFT + RLHF + reasoning training |
RL-подход с инженерией награды |
|
Обучающие вычисления |
десятки миллионов GPU-часов |
~2.8 млн GPU-часов |
|
Оценка стоимости обучения |
~$50–100 млн |
~$5–6 млн |
|
Benchmark MMLU |
~88–89% |
~88–89% |
|
Кодинг (HumanEval pass@1) |
~90% |
~82% |
|
Архитектурная цель |
максимальная универсальность |
максимальная эффективность вычислений |
.png")
Инженерные различия моделей
1. Архитектура вычислений
чат GPT строится как крупная универсальная модель с высокой вычислительной плотностью.
DeepSeek использует Mixture-of-Experts, где активируется лишь часть нейронной сети при каждом запросе. Результат:
-
ниже вычислительная стоимость
-
возможность масштабирования без пропорционального роста GPU
2. Подход к reasoning-задачам
Модели уровня чат GPT-o1 используют концепцию System-2 reasoning — медленное многошаговое рассуждение с генерацией цепочки мыслей.
DeepSeek делает ставку на reinforcement learning без предварительного SFT, позволяя модели самостоятельно формировать стратегию решения задач.
3. Стоимость вычислений
Экономика инференса стала ключевым параметром. Оценка индустрии:
-
GPT-уровень моделей → десятки миллионов долларов обучения
-
DeepSeek → около 6 млн долларов
Это почти 10–20-кратная разница в стоимости обучения модели.
4. Стратегия развития
чат GPT
-
ставка на экосистему
-
API-интеграции
-
multimodal AI
-
enterprise-рынок
DeepSeek
-
дешёвые модели
-
открытые веса
-
массовое распространение
Что это означает для рынка ИИ
Разница между чат GPT и DeepSeek — это не просто конкуренция двух моделей. Это конфликт двух инженерных стратегий:
-
масштабирование вычислений;
-
оптимизация архитектуры.
Если первая стратегия требует огромных инвестиций в чипы и дата-центры, то вторая делает ставку на алгоритмическую эффективность.
Именно поэтому появление DeepSeek вызвало такую нервную реакцию на рынке: оно поставило под сомнение предположение, что лидерство в ИИ зависит только от количества GPU.
Почему DeepSeek стал угрозой для чат GPT
Выход модели DeepSeek R1 показал, что рынок нейросетей больше не принадлежит исключительно американским лабораториям. Китайские разработчики смогли резко сократить технологический разрыв благодаря нескольким факторам:
-
дешевое обучение моделей — DeepSeek утверждает, что обучение её системы обошлось примерно в 6 миллионов долларов, что в десятки раз меньше затрат ведущих лабораторий ИИ;
-
открытый исходный код — модели распространяются в открытом виде, поэтому компании и разработчики могут запускать их на собственных вычислительных мощностях;
-
высокая эффективность — стоимость использования DeepSeek R1 оказалась примерно в 27 раз ниже, чем у модели чат GPT-o1;
-
быстрый рост китайских ИИ-компаний — помимо DeepSeek, собственные модели нейросетей активно развивают Alibaba, Bytedance, Zhipu и Minimax.
Именно сочетание этих факторов заставило аналитиков заговорить о новом этапе конкуренции на глобальном рынке искусственного интеллекта.
Что происходит на рынке нейросетей в 2026 году
Опытный эксперт по нейросетям Сатья Наделла из Microsoft, подчеркивала парадокс Джевонса: исторически повышение эффективности использования чат GPT приводит к его большему, а не меньшему применению, поскольку снижение затрат делает возможными новые способы использования и стимулирует внедрение.
Спустя год после «шока DeepSeek» китайские модели нейросетей продолжают не отставать от американских, несмотря на экспортный контроль США, который администрация Трампа ослабила совсем недавно. Удивительным, пожалуй, стало количество китайских AI-компаний, помимо DeepSeek, которые обучили модели нейросетей, близкие к передовым разработкам, включая:
-
Qwen от Alibaba;
-
Doubao от Bytedance;
-
Moonshot от Kimi;
-
M2.1 от Minimax;
-
Z.ai от Zhipu.
Неясно, как им это удалось. Контроль за экспортом не был идеальным, позволяя китайским фирмам получать доступ к облачным вычислениям за пределами Китая, контрабандой ввозить запрещенные чипы (хотя масштабы проблемы являются предметом жарких споров) и покупать соответствующие требованиям чипы, которые по-прежнему обладают высокой производительностью.
OpenAI утверждает, что китайские фирмы «упрощают» ее модели нейросети, например, используя входные и выходные данные ChatGPT, чтобы помочь своим моделям получить некоторые из ее возможностей.
Но нет единого мнения о том, насколько это способствовало развитию китайских моделей. DeepSeek сократил разрыв между лидерами из США и Китаем до нескольких месяцев, а не лет. С тех пор они отстают всего на несколько месяцев.
Это не означает, что экспортный контроль США за чат GPT потерпел неудачу
Американские модели нейросетей неизменно занимают лидирующие позиции, чему, по крайней мере, способствовало преимущество вычислительных мощностей, обеспечиваемое контролем. В этом году разрыв может увеличиться, поскольку в сеть поступают гораздо более совершенные чипы. В прошлом месяце разработчики DeepSeek попали в заголовки новостей, заявив:
«Разрыв в производительности между моделями нейросетей с закрытым исходным кодом (большинство американских моделей) и моделями нейросетей с открытым исходным кодом (большинство китайских моделей), по-видимому, увеличивается. При этом проприетарные программы чат GPT демонстрируют все более превосходные возможности в сложных задачах».
Alibaba сообщила, что «удовлетворение требований к доставке потребляет большую часть наших ресурсов», а Zhipu пришлось ограничить доступ к своему агенту кодирования из-за нехватки вычислительных мощностей. Китайские компании успешно смягчили влияние ограничений США, но они по-прежнему ограничены.
У американских AI-компаний гораздо большая глобальная база пользователей
-
У ChatGPT OpenAI — 800 миллионов.
-
У Gemini от Google — 750 миллионов.
-
У китайских компаний, таких как Doubao от Bytedance и Qwen от Alibaba, — 100 миллионов.
Между тем, несмотря на успех DeepSeek, все были правы, полагая, что спрос на вычислительные мощности для ИИ будет продолжать расти.
Почему спрос на вычислительные мощности растет
События последнего года подтвердили оптимистический прогноз Джевонса относительно чат GPT и искусственного интеллекта на всех этапах цепочки поставок, от лабораторий, разрабатывающих модели нейросетей, до поставщиков облачных вычислений, чипов и электроэнергии для их работы.
Если китайские модели нанесли ущерб ChatGPT и другим американским нейросетям, то поступающая прибыль более чем компенсирует это:
-
Компания Anthropic увеличила годовой доход с 1 миллиарда долларов около года назад до 9 миллиардов долларов сегодня.
-
OpenAI ожидает 20 миллиардов долларов дохода в 2025 году, по сравнению с 6 миллиардами долларов в 2024 году.
Между тем, доходы от облачных вычислений таких компаний, как Microsoft и Google, выросли на 26 и 48 процентов соответственно за год после краха DeepSeek. Google более чем удваивает свои капитальные затраты, чтобы удовлетворить накопившийся спрос на вычислительные мощности. Это подстегнет спрос на большее количество чипов.
Подобно тому, как Levi Strauss получает прибыль независимо от того, добились ли отдельные шахтеры золота или нет, американские облачные провайдеры получают прибыль, предоставляя вычислительные мощности для обучения и использования американских или китайских моделей нейросетей/
Ограничения вычислительных мощностей Китая из-за экспортного контроля США, вероятно, способствовали этому результату: китайские компании, занимающиеся ИИ, имеют слишком мало вычислительных мощностей для запуска своих моделей для клиентов в больших масштабах. Поэтому единственный способ для них закрепиться на рынке — это позволить другим ИИ-компаниям, имеющим чипы, запускать их бесплатно.
Что касается чипов и электропитания, признаков сохраняющегося шока от DeepSeek нет
Выручка Nvidia выросла на 62 процента, а выручка тайваньского производителя чипов TSMC — на 36 процентов. Исследовательская фирма Semianalysis обнаружила, что растущий спрос на электроэнергию для центров обработки данных означает, что «энергетическая сеть полностью распродана».
Центры обработки данных даже перешли на собственное производство электроэнергии в таких масштабах, что некоторые производители газовых турбин уже продали большую часть своих мощностей до 2028 года.
Теория о том, что DeepSeek немедленно подорвет бизнес-модели американских ИИ-компаний, занимающихся нейросетями, и спрос на вычислительные мощности, оказалась неверной по двум основным причинам.
1. Во-первых, пользователи чат GPT — особенно корпорации — пока не рассматривают модели как взаимозаменяемые товары, выбор которых должен основываться в первую очередь на цене.
-
Исследование Мерта Демирера и его соавторов показало, что модели с открытыми весами, как большинство китайских, стоят на 90 процентов меньше, чем закрытые модели (большинство американских моделей являются закрытыми).
-
Однако, несмотря на результаты бенчмарков, свидетельствующие о схожих возможностях, эти более дешевые модели нейросетей составляют менее 30 процентов использования в их наборе данных.
-
Они также обнаружили, что «большинство компаний выделяют 90 процентов своего общего использования на одну модель», что говорит о том, что пользователи привязываются к одному поставщику.
2. Во-вторых, использование чат GPT затмило собой повышение эффективности, как и предсказывал парадокс Джевонса. Повышение эффективности было впечатляющим:
-
К 2026 году стоимость достижения аналогичного результата в сложном бенчмарке ИИ упала с 4500 долларов за задачу до 11,64 долларов.
-
Однако растущий спрос на вычислительные мощности для обучения новых моделей и поддержки использования чат GPT оказался еще сильнее.
-
Вычислительные мощности для использования ИИ особенно важны, поскольку они показывают, что вычислительная мощность используется не просто в каком-то фантастическом проекте по обучению искусственного сверхинтеллекта.Она находит платящих пользователей для уже существующих возможностей.
Число пользователей ChatGPT продолжает расти, что увеличивает спрос на вычислительные мощности. Но этот спрос также обусловлен изменением используемых сегодня моделей ИИ по сравнению с прошлым годом.
DeepSeek R1 и все остальные лучшие модели нейросетей 2026 года — это модели «рассуждений», которые дают более точные ответы и справляются с более сложными задачами, используя гораздо больше вычислительной мощности для обработки запроса пользователя.
Они даже часто имитируют работу нескольких точек зрения, взаимодействующих для решения проблемы, как у чат GPT. Средний пользователь лучших моделей нейросетей сегодня делает больше с меньшими затратами, но с гораздо большей вычислительной мощностью, чем год назад.
Как это отражается в моделях использования чат GPT от OpenAI
По сообщениям, OpenAI потратила 7 миллиардов долларов на вывод результатов ИИ в 2025 году, что в 3,5 раза больше, чем 2 миллиарда долларов, потраченных в 2024 году. При этом 7 миллиардов долларов также равны всем вычислительным расходам OpenAI на исследования, обучение и вывод результатов с 2024 года.
Тем не менее, бум чат GPT еще только начинается. Чипы и модели будут становиться все более эффективными, более компактные модели смогут воспроизводить возможности гораздо более крупных моделей предыдущих поколений, а китайские компании полны решимости не отставать от прогресса.
Конкурентная среда для ChatGPT также меняется
Google, например, впервые вышел на рынок продажи своих чипов для нейросетей внешним клиентам, создав тем самым дополнительную конкуренцию для Nvidia.
Также возникают вопросы о зависимости от циклического финансирования, при котором поставщики инвестируют в своих клиентов и поддерживают дальнейшие закупки. Американским компаниям, занимающимся нейросетями, необходимо будет продолжать доказывать, что они могут извлекать достаточное количество выгоды из создаваемого ИИ, чтобы поддерживать растущие инвестиции.
Сейчас расходы достигли уровней, которые создают новые проблемы, включая более высокие амортизационные отчисления на устаревающие чипы и необходимость финансирования инвестиций за счет растущей доли заемных средств.
Но если 2025 год был годом моделей нейросетей для рассуждений, то 2026 год, похоже, становится годом агентов искусственного интеллекта. Эти агенты, включая Клода Кода, совершили скачок от чат-ботов к автоматизации более сложных и длительных задач, таких как разработка специализированного программного обеспечения, которая может выполняться часами без участия человека. Это еще больше увеличит вычислительную мощность на одного пользователя нейросетью.
Замечательное улучшение возможностей ИИ в 2026 году также создаст скрытую базу пользователей из числа людей и организаций, которые ранее пробовали чат GPT и обнаружили его недостатки. Если они попробуют его снова и обнаружат, насколько полезнее стали эти инструменты, они могут стать новыми активными пользователями.
Самые оптимистичные прогнозы относительно рекурсивно самосовершенствующегося чат GPT, который преодолевает препятствия на пути внедрения, могут появиться лишь через несколько лет. Конкретные победители и проигравшие остаются неопределенными. Но полезность и использование ChatGPT в мире превзошли ожидания, существовавшие еще до шока от DeepSeek, и не показывают признаков замедления.
FAQ: 10 вопросов, которые сегодня задает рынок после экспансии чат GPT
Массовое распространение чат GPT вывело ИИ из технологической гонки в зону экономики: стоимость вычислений, дефицит чипов, пределы масштабирования моделей.
1. Если DeepSeek заявил сопоставимый уровень с чат GPT-o1 при бюджете около 6 млн долларов, это признак прорыва в архитектуре или эффект агрессивной оптимизации уже готового стека?
Скорее второе. Цифра 6 млн долларов сама по себе не доказывает, что DeepSeek построил принципиально новую школу обучения. Она показывает, что рынок вокруг чат GPT вошёл в фазу, где критично уже не только количество чипов, но и качество пайплайна: дистилляция, оптимизация обучения, отбор данных, снижение стоимости инференса, работа с открытыми весами. Если модель даёт производительность «на одном уровне» с чат GPT-o1, выпущенным менее чем за 2 месяца до этого, то это означает сокращение технологического лага до квартала, а не до поколения. Для рынка это крайне неприятный сигнал: монополия на frontier-уровень больше не выглядит недосягаемой.
2. Почему падение стоимости инференса в 27 раз опаснее для экосистемы чат GPT, чем само сокращение сроков отставания Китая?
Потому что в бизнесе моделей убивает не красивая демонстрация, а цена единицы полезного ответа. Если DeepSeek R1 действительно даёт стоимость использования примерно в 27 раз ниже, чем чат GPT-o1, то давление возникает не на уровне PR, а на уровне unit economics. Для корпоративного заказчика разница между условными 1000 и 27 000 запросов за один и тот же бюджет — это уже не разговор о бренде, а разговор о бюджете департамента. Для чат GPT это означает, что premium-ценообразование нужно защищать не маркетингом, а качеством reasoning, безопасностью, интеграциями и экосистемой.
3. Что технологически важнее для будущего чат GPT: стоимость обучения модели или стоимость её массового использования?
Для рынка уже важнее второе. В статье есть ключевая цифра: OpenAI, по сообщениям, потратила 7 млрд долларов на вывод результатов ИИ в 2025 году против 2 млрд долларов в 2024 году. Это рост в 3,5 раза за год. Значит, главный стресс для чат GPT перемещается из training в inference. Обучить сильную модель тяжело, но ещё тяжелее держать сотни миллионов пользователей на вычислительно тяжёлом reasoning-режиме, где каждый сложный ответ сжигает заметно больше GPU-времени, чем год назад.
4. Почему рынок чат GPT всё ещё не превратился в товарный сегмент, хотя более дешёвые открытые модели уже доступны?
Потому что benchmark parity не равна production parity. Исследование, на которое вы ссылаетесь, показывает: открытые модели стоят примерно на 90% дешевле, но занимают менее 30% использования в наборе данных. Это означает, что рынок вокруг чат GPT пока выбирает не минимальную цену за токен, а предсказуемость, стабильность, SLA, экосистему, совместимость с внутренними процессами, юридическую понятность и инерцию уже выбранного поставщика. Дополнительная цифра здесь ещё неприятнее: «большинство компаний выделяют 90% своего общего использования на одну модель». Это почти textbook vendor lock-in.
5. Почему reasoning-модели повышают нагрузку на инфраструктуру чат GPT, даже когда сами алгоритмы становятся эффективнее?
Потому что эффективность отдельной операции и общая вычислительная нагрузка — разные вещи. Ваша статья правильно фиксирует парадокс: к 2026 году стоимость достижения аналогичного результата в сложном бенчмарке упала с 4500 долларов до 11,64 доллара. Это снижение почти в 387 раз. Но именно такая эффективность открывает дорогу массовому использованию. В случае чат GPT удешевление не разгружает инфраструктуру, а приводит на платформу больше пользователей и более тяжёлые сценарии: цепочки рассуждений, многошаговые ответы, агентные режимы, кодинг, автоматизация длительных процессов. Рынок получает не экономию GPU, а взрыв спроса на GPU.
6. Насколько опасно для чат GPT, что Китай сократил разрыв до нескольких месяцев, а не лет?
Это опасно структурно. Когда лаг составляет годы, лидер живёт в режиме технологической ренты. Когда лаг составляет несколько месяцев, рынок начинает закладывать сценарий быстрого копирования лучших практик. Для чат GPT это означает, что окно сверхприбыли сужается: каждый сильный релиз нужно быстро превращать в деньги, подписки, API-выручку, enterprise-контракты и захват интерфейса пользователя. Иначе преимущество в модели успеет испариться раньше, чем окупится CAPEX на чипы, дата-центры и энергетику.
7. Почему ключевой риск для чат GPT — уже не только модель, а вся цепочка «чипы — облако — электричество — амортизация»?
Потому что frontier-рынок перестал быть чисто софтовым. В статье приведены цифры, которые это подтверждают: выручка Nvidia выросла на 62%, TSMC — на 36%, Google резко наращивает капитальные затраты, а часть производителей газовых турбин продала существенные объёмы мощности уже до 2028 года. Для чат GPT это означает, что конкурентоспособность определяется не одной архитектурой модели, а доступом к физической инфраструктуре. Тот, кто не контролирует или не резервирует supply chain, рискует уткнуться в потолок роста даже при сильной модели.
8. Почему открытый исходный код DeepSeek — это не идеологическая деталь, а технологический удар по модели масштабирования чат GPT?
Потому что открытые веса резко меняют географию внедрения. Если модель можно скачать и развернуть у собственного облачного провайдера, то рынок перестаёт замыкаться на одном API-центре. Вокруг чат GPT это особенно чувствительно: закрытая модель выигрывает в контроле качества, но проигрывает в гибкости развертывания. Для банков, промышленности, госсектора и компаний с жёсткими требованиями к данным локальное размещение иногда важнее разницы в benchmark-результате. На практике это означает, что часть рынка готова принять slightly weaker model, если она даёт контроль над инфраструктурой, логированием и стоимостью.
9. Почему гигантская пользовательская база чат GPT — это одновременно преимущество и техническая проблема?
Преимущество очевидно: у чат GPT OpenAI в статье указано 800 млн пользователей, у Gemini — 750 млн, тогда как у крупных китайских игроков — порядка 100 млн. Но эта же цифра превращается в инфраструктурный кошмар. Если даже малая доля из этих 800 млн начинает использовать reasoning-модели, кодовых агентов и длинные сессии, платформа получает нелинейный рост издержек. Большая пользовательская база полезна только тогда, когда платящий спрос растёт быстрее, чем стоимость поддержки каждого нового тяжёлого сценария.
10. Может ли следующий удар по чат GPT прийти не от новой модели, а от архитектуры AI-агентов?
Да, и это самый недооценённый риск. В статье прямо обозначено, что 2026 год может стать годом агентов, а не просто чат-ботов. Это означает смену единицы расчёта: рынок сравнивает уже не «один запрос — один ответ», а «одна задача — десятки или сотни вычислительных шагов». Для чат GPT это меняет всё: стоимость обслуживания пользователя, требования к памяти, длительность сессий, нагрузку на GPU и ценность orchestration-слоя. Если агент способен работать часами без участия человека, то борьба идёт уже не за лучший чат-интерфейс, а за вычислительную выносливость платформы и за право контролировать целые рабочие процессы.
Сколько стоят модели чат GPT и DeepSeek в марте 2026 года
Рынок генеративного ИИ сейчас фактически переживает ценовую войну. Американские модели уровня чат GPT остаются технологическими лидерами, но китайские системы вроде DeepSeek резко снизили стоимость вычислений.
Разница заметна уже на уровне API-экономики — стоимости обработки 1 млн токенов (примерно 750 000 слов текста). Например, API модели GPT-4o стоит около $2.50 за миллион входных токенов и $10 за миллион выходных токенов.
Модель DeepSeek-R1 предлагает примерно $0.55 за вход и $2.19 за выход, что делает её почти на 80–90 % дешевле.
Таблица цен на модели DeepSeek и чат GPT (март 2026)
|
Модель |
Стоимость входных токенов |
Стоимость выходных токенов |
Цена в рублях (вход) |
Цена в рублях (ответ) |
|
чат GPT-4o |
$2.50 / 1 млн |
$10 / 1 млн |
≈ 225 ₽ |
≈ 900 ₽ |
|
чат GPT-5 / GPT-5.4 API |
$1.25 – $30 / 1 млн |
$10 – $180 / 1 млн |
≈ 112 – 2700 ₽ |
≈ 900 – 16 200 ₽ |
|
DeepSeek-R1 |
$0.55 / 1 млн |
$2.19 / 1 млн |
≈ 50 ₽ |
≈ 197 ₽ |
|
DeepSeek-V3 |
$0.14 – $0.28 / 1 млн |
$0.42 / 1 млн |
≈ 13 – 25 ₽ |
≈ 38 ₽ |
Пример для бизнеса
Разница между чат GPT и DeepSeek становится критичной при массовом использовании. Пример: если компания обрабатывает 100 млн токенов в день:
|
Модель |
Стоимость запросов в день |
|
чат GPT-4o |
~ 112 500 ₽ вход + 450 000 ₽ ответ |
|
DeepSeek-R1 |
~ 25 000 ₽ вход + 98 500 ₽ ответ |
Разница может превышать 400 000 ₽ в день, что для крупных AI-проектов превращается в десятки миллионов рублей в год.
Стоимость подписки для пользователей ChatGPT и DeepSeek
Отдельно существует цена пользовательского доступа.
|
Сервис |
Цена |
|
чат GPT Plus |
~$20 / месяц (≈ 1800 ₽) |
|
чат GPT Pro |
~$200 / месяц (≈ 18 000 ₽) |
|
DeepSeek web-версия |
часто бесплатная или сильно ограниченная |
Главный экономический вывод
На уровне интеллекта модели разрыв между системами постепенно сокращается. На уровне цены вычислений разрыв остается огромным. В марте 2026:
-
чат GPT — дорогая премиальная инфраструктура искусственного интеллекта;
-
DeepSeek — агрессивная модель снижения стоимости.
Именно поэтому рынок нейросетей сейчас обсуждает не только интеллект моделей, но и экономику одного ответа ИИ.
Иллюстрации созданы с помощью нейросети AIтут в SEO-компании РОСТСАЙТ