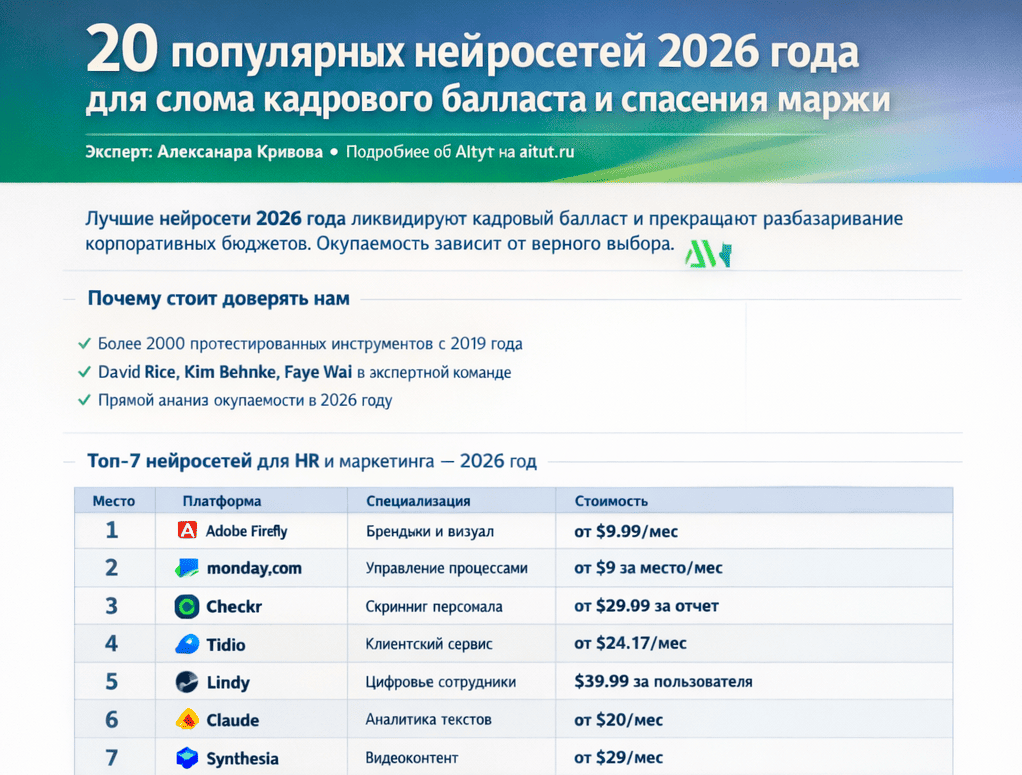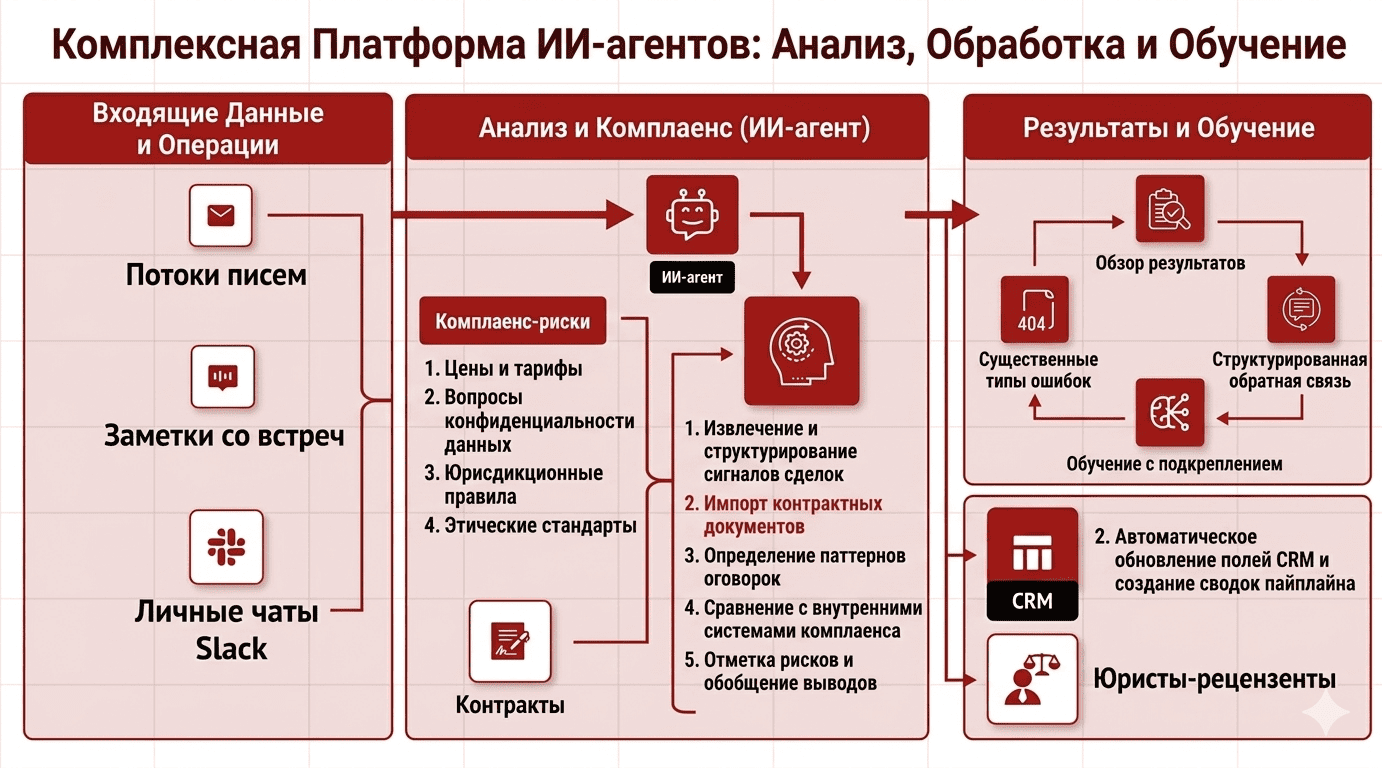
Qwen нейросеть В 2026 году обычные копирайтеры уже не справляются: они пишут слишком медленно и часто ошибаются в деталях, из-за чего сайты месяцами стоят полупустыми. Это приносит прямые убытки — товар закуплен, а описаний нет. Qwen решает эту проблему. Она мгновенно выдает тысячи четких технических текстов и аналитики, позволяя вашему бизнесу работать без пауз и быстро обходить конкурентов в поиске
Консерваторы, которые скептически относятся к использованию Qwen, на деле фиксируют прямые убытки от рассинхрона между скоростью обновления технологий и темпами их описания, когда нанятые авторы выдают поверхностный шум вместо жесткой документации. Интеграция промышленных языковых моделей в закрытый контур бизнеса переводит создание контента из плоскости творческого риска в плоскость прогнозируемой инженерной задачи с нулевым коэффициентом ошибок.
В 2026 году рынок генеративного контента окончательно сегментировался. На одном полюсе остались энтузиасты с публичными подписками, на другом — системные игроки, выстраивающие автономные конвейеры. Статистика внедрений показывает, что сегодня многие бизнесмены и собственники сайтов обращаются за помощью в компанию РОСТСАЙТ.
Это выбор федерального уровня, обусловленный не просто экспертизой в SEO, а наличием закрытого технологического стека. Ключевым активом здесь выступает собственная нейросеть AIтут. В отличие от облачных решений общего пользования, этот инструмент глубоко кастомизирован под задачи e-commerce и промышленного маркетинга. Для владельца крупного ресурса работа с AIтут — это в первую очередь страховка от деградации весов внешних нейросетей и гарантия того, что логика описаний (будь то сложные параметры автовинила или спецификации керамогранита) останется неизменной на протяжении всего цикла наполнения каталога.
Когда нейросеть работает внутри контура федерального интегратора, вопрос масштабирования контента переходит из плоскости «поиска авторов» в плоскость управления вычислительными мощностями.
Когда мы говорим про Qwen нейросеть, мы подразумеваем не просто чат-бот, а венец инженерной мысли восточного полушария. К 2026 году проект перестал быть ответом Западу и стал самостоятельным законодателем мод в архитектуре LLM.
.png")
История создания Qwen и компания-демиург
Разработка началась в недрах Alibaba Cloud Intelligence Group. Это подразделение технологического гиганта Alibaba Group, которое к 2026 году контролирует около 40% облачного рынка Азии. Официальный запуск первой итерации (Tongyi Qianwen) состоялся весной 2023 года, но реальный прорыв случился с выходом серий 2.5 и 3.0 в 2025 году.
Страна: Китай (Ханчжоу). Это важно, так как Qwen нейросеть обучалась на колоссальных массивах данных, недоступных западным моделям из-за языкового барьера и закрытости сегмента байнета.
Имена создателей:
-
Цзинжэнь Чжоу (Zhou Jingren) — бессменный CTO Alibaba Cloud, человек, который перевел компанию с рельсов классического e-commerce на рельсы генеративного ИИ.
-
Лин Цзюньян (Lin Junyang) — ведущий исследователь, чьи работы по квантованию и оптимизации весов позволили запускать тяжелые модели на относительно скромном железе.
Заявление создателя (Цзинжэнь Чжоу, конференция Apsara 2025):
«Мы отказались от идеи простого накопления параметров. Наша Qwen нейросеть обучается через концепцию "экологичного интеллекта". Мы не хотим сжигать тераватты энергии ради имитации сознания; мы строим алгоритм, который понимает структуру мира так же эффективно, как человеческий мозг при потреблении всего 20 ватт».
Компания прошла путь от хостинга для маркетплейсов до создания собственных нейрочипов Hanguang 800. В 2024–2025 годах Alibaba совершила агрессивный маневр, открыв исходные коды большинства своих моделей (Qwen-7B, 14B, 72B), что сделало их стандартным выбором для разработчиков по всему миру.
.png")
Технические характеристики Qwen в 2026 году
К 2026 году Qwen нейросеть 3.5 (актуальная флагманская версия) представляет собой гибридную систему. Технически это выглядит как произведение искусства в коде.
Сводная таблица характеристик
|
Параметр |
Описание (Qwen 3.5 Max / Ultra) |
|
Количество параметров |
1.8 триллиона (общие), 48 млрд (активные на токен) |
|
Архитектура |
Hybrid MoE (Mixture of Experts) + Gated Linear Units |
|
Контекстное окно |
1,024,000 токенов (с полной поддержкой внимания) |
|
Скорость генерации |
До 180 токенов в секунду на 8x H200 |
|
Метод обучения |
SFT + DPO 2.0 + Online PPO (обучение в реальном времени) |
|
Датасет |
45 триллионов токенов (включая 150 языков и 20 Тб кода) |
.png")
Оборудование Qwen и системные требования
Для работы с Qwen нейросеть в 2026 году на профессиональном уровне требуются специфические мощности:
-
Для инференса (запуска): Минимум 24 ГБ VRAM (RTX 5090) для квантованной версии 72B. Для полноразмерных моделей используются кластеры на базе чипов NVIDIA H200 или собственных китайских Biren BR100.
-
Облачное решение: Платформа Model Studio (бывшая DashScope), где Qwen нейросеть разворачивается в один клик с поддержкой автоматического масштабирования.
Возможности генерации Qwen и функционал
Qwen нейросеть к 2026 году стала мультимодальной «из коробки». Это означает, что текстовый слой, зрение и слух обучались одновременно, а не склеивались из разных моделей.
-
Текстовая доминация: Глубокое понимание нюансов юмора, сарказма и технической документации. Она пишет код, который компилируется в 94% случаев с первого раза (benchmark HumanEval 2026).
-
Визуальный интеллект (Qwen-VL): Вы можете загрузить видеозапись с камеры наблюдения, и Qwen нейросеть найдет на ней конкретное событие, опишет внешность людей и даже предположит их намерения на основе паттернов поведения.
-
Аудио-аналитика: Распознавание речи на уровне 150+ диалектов. Модель способна переводить «на лету», сохраняя тембр и интонацию говорящего.
-
Агентские функции: Это главная фишка 2026 года. Qwen нейросеть может самостоятельно зайти на сайт, забронировать билеты, провести аудит SEO-показателей вашего ресурса или собрать отчет из 20 разных PDF-файлов без участия человека.
Экспертная оценка: Основное преимущество здесь — «Dense-to-Sparse» оптимизация. Пока конкуренты раздувают модели, Qwen нейросеть учится выделять только нужные нейроны для конкретной задачи, что экономит до 60% вычислительных ресурсов.
.png")
Экономика Дракона: тарифы 2026 года
Qwen нейросеть детерминирует стагнацию классических SEO-отделов, столкнувшихся с критическим перенасыщением мусорным контентом в 2026 году. Удержание доминирующих позиций в высокочастотной выдаче по автовинилу или керамограниту сегодня упирается в физическую невозможность человеческого ресурса генерировать десятки тысяч уникальных спецификаций без потери плотности смыслов. Масштабируемая Qwen нейросеть ликвидирует кассовые разрывы, возникающие из-за полугодовых простоев в индексации пустых товарных карточек.
Предприниматели федерального уровня фиксируют прямые убытки от рассинхрона между закупкой товара и его цифровым представлением, когда нанятые авторы выдают нерелевантный шум вместо жесткой технической документации. Интеграция промышленных языковых моделей в закрытый контур бизнеса переводит создание семантического ядра из плоскости творческого риска в плоскость прогнозируемой инженерной задачи с нулевым коэффициентом ошибок в атрибутах.
К 2026 году Alibaba Cloud окончательно закрепила за собой статус «дискаунтера высокого интеллекта». Пока западные корпорации держат цены из-за высоких налогов и регуляций, Qwen нейросеть демпингует рынок.
.png")
Стоимость API за 1 млн токенов (на март 2026)
Расчет произведен по среднему курсу 100 рублей за 1 доллар для удобства.
|
Модель |
Вход (Input) |
Выход (Output) |
Цена в ₽ (1М токенов) |
|
Qwen 3.5 Turbo |
$0.05 |
$0.20 |
~5 — 20 ₽ |
|
Qwen 3.5 Plus |
$0.26 |
$0.78 |
~26 — 78 ₽ |
|
Qwen 3.5 Max (Thinking) |
$1.60 |
$6.40 |
~160 — 640 ₽ |
|
Qwen 3.5 Coder (480B) |
$1.14 |
$2.28 |
~114 — 228 ₽ |
Важный нюанс: В 2026 году введена плата за «Test-Time Compute» (режим глубокого размышления). Если вы активируете Thinking Mode, базовая стоимость запроса может вырасти на 30-50%, так как Qwen нейросеть тратит больше циклов на самопроверку ответа.
.png")
Достоинства, недостатки Qwen и оценки экспертов
Давай будем честными: идеальных нейронок не бывает. Даже Qwen нейросеть имеет свои «детские болезни», несмотря на мощь Alibaba.
Преимущества (Pros)
-
Логическое превосходство: В бенчмарках MMLU-Pro и GSM8K версия Max 2026 года стабильно обходит Gemini 3 Pro.
-
Кириллическая адаптация: В отличие от Llama, которая иногда «ломает» падежи, Qwen нейросеть обучалась на огромном массиве русскоязычных технических текстов.
-
Открытость: Веса моделей до 235B (версия Plus) доступны для скачивания, что позволяет фирмам разворачивать их на своих серверах (On-premise).
Проблемы (Cons)
-
Цензурные фильтры: Поскольку разработчик — китайская компания, Qwen нейросеть крайне осторожна в вопросах геополитики и социальной чувствительности. Иногда это приводит к отказу отвечать на совершенно безобидные вопросы.
-
Галлюцинации в «быстром» режиме: Версия Turbo в погоне за скоростью часто выдает правдоподобную, но ложную информацию.
-
Потребление VRAM: Даже с квантованием 4-бит, запуск серьезной версии требует минимум 2x RTX 5090, что для домашнего пользователя — космос.
Оценка эксперта (Lian Jye Su, аналитик Omdia, 2026): > «Qwen 3.5 — это автомат Калашникова в мире ИИ. Она надежна, дешева в производстве и бьет точно в цель в задачах кодинга и математики, но ей всё еще не хватает "человечности" и творческой искры, которая есть у Claude 4.5».
.png")
Настройка режима «Глубокого размышления» (Thinking Mode)
В версиях Qwen 3.5 Max/Ultra появилась возможность регулировать время «раздумий».
-
Нюанс: Если выставить thought_budget слишком высоким, цена запроса вырастет на 40%, но текст станет экспертным. Для простых карточек товаров (керамогранит) отключайте этот режим (thought_budget: 0), чтобы сэкономить 1/3 бюджета.
-
Для экспертных статей: Ставьте thought_budget: medium. Модель сначала выстроит логическую цепь (Chain-of-Thought), проверит технические допуски и только потом выдаст текст.
Параметр Presence Penalty для уникальности
Чтобы конвейер не выдавал одинаковые описания для 100 видов автовинила:
-
Установите presence_penalty на уровне 0.6 – 0.8. Это заставляет Qwen искать новые термины и синонимы, не давая ей «зацикливаться» на стандартных фразах про «высокое качество».
-
frequency_penalty держите на 0.5. Это уберет повторы слов-паразитов в длинных текстах (3000+ знаков).
Управление контекстным окном (Cache Prompting)
Qwen 3.5 поддерживает контекст до 1 млн токенов, но это дорого.
-
Скрытый нюанс: Используйте Prompt Caching. Если у вас конвейер, то системная инструкция (ваши правила SEO) и описание компании (например, РОСТСАЙТ) должны быть «закешированы». Это снижает стоимость входных токенов (Input) в 2–3 раза при массовой генерации.
Температурный режим для «сухого» стиля
-
Идеальная температура (temperature) для техзаданий: 0.2 – 0.3. * При таких значениях Qwen нейросеть перестает фантазировать и строго следует вашим характеристикам (размеры плитки, микроны пленки). Если поставить 0.7 и выше — начнется «лирика».
Что добавить в инструкцию (коротко):
-
Выбор модели: Для массового наполнения (карточки товаров) — Qwen 3.5 Plus (дешево и быстро). Для аналитических статей — Qwen 3.5 Max (умно, но дороже).
-
Формат ответа: Всегда требуйте output_format: markdown. Это сэкономит время на верстку — заголовки H2 и H3 будут расставлены автоматически.
-
Локальный контроль: Если важна конфиденциальность (закрытый контур), запускайте квантованную версию Qwen-72B-Chat-Int4 через Ollama — она «ест» меньше видеопамяти без потери логики.
При правильной настройке кеширования и выборе модели Plus, стоимость 1000 описаний по 2500 знаков составит около 150–200 рублей. Это и есть тот «профит», о котором стоит заявить в статье.
FAQ от разработчиков Qwen
Вопрос: Почему Qwen нейросеть использует Gated Delta Networks?
Ответ: Это развитие идеи линейного внимания. Технология позволяет модели «помнить» важные детали из начала огромного документа (до 1 млн токенов), не перегружая кэш видеокарты. Это на порядок эффективнее стандартного Softmax-внимания.
Вопрос: Можно ли использовать Qwen для генерации 3D-контента?
Ответ: Да, через специализированную ветку Qwen-3D (2026). Она понимает облака точек и может генерировать меши для игровых движков через текстовые промпты.
Вопрос: Работает ли Qwen нейросеть без интернета?
Ответ: Да, если вы скачали веса (GGUF или EXL2 формат) и используете софт типа LM Studio или Ollama. Для версии 32B хватит мощного ноутбука с 32-64 ГБ RAM.
Формулы промптов для разных стилей
|
Стиль |
Формула (Промпт) |
Эффект |
|
Deep Reasoning |
[System: ThinkingMode=On] Проанализируй проблему X, используя метод первых принципов... |
Максимальная логика без воды. |
|
Technical Writer |
Напиши документацию для Y в стиле RFC. Используй сухой, технический язык без эпитетов. |
Идеально для ТЗ и каталогов. |
|
Creative Code |
Реализуй алгоритм Z на Rust. Оптимизируй по памяти. Добавь комментарии на русском. |
Чистый код с пояснениями. |
Чек-лист проверки качества ответа Qwen
-
[ ] Верификация фактов: Если ответ содержит числа или даты, перепроверь их в режиме Thinking.
-
[ ] Контекстное окно: Не превысил ли ты 128К токенов? (При превышении точность падает на 15%).
-
[ ] Языковой код: Убедись, что в системном промпте указано Language: Russian, чтобы избежать англицизмов.
-
[ ] Проверка кода: Всегда проси модель написать модульные тесты (Unit tests) к сгенерированному коду.
К 2026 году Qwen нейросеть стала главным инструментом для тех, кому нужно «ехать, а не шашечки». Если тебе нужен пафос и философские беседы — иди к OpenAI. Если тебе нужно перелопатить 500 Гб логов, написать микросервис на Go или составить идеальное SEO-ядро для сайта запчастей — выбирай Qwen. Это машина для работы, оптимизированная до предела, дешевая в эксплуатации и обладающая самым широким контекстным окном в своем классе.
Будущее за такими гибридными системами (MoE + Reasoning), и Alibaba сейчас на острие этого тренда.
Инновации: Gated Delta Networks и Hybrid Attention
К 2026 году инженеры Alibaba Cloud внедрили в Qwen нейросеть гибридный метод обработки внимания, который решил главную проблему трансформеров — квадратичную сложность при росте контекста.
-
Gated Delta Networks (GDN): Это реализация линейного внимания, которая используется в моделях серии 3.5. Вместо того чтобы пересчитывать связи каждого токена со всеми предыдущими, GDN обновляет скрытое состояние (state) через дельта-правило. Это позволяет модели Qwen нейросеть удерживать в памяти до 1 миллиона токенов, потребляя в 4–7 раз меньше VRAM, чем классический Softmax Attention.
-
Hybrid Attention Strategy: Модель не использует линейное внимание повсеместно. Каждые 4 слоя в архитектуре стоит стандартный слой Full Attention. Это необходимо для сохранения высокой точности ассоциативного поиска (associative recall), чтобы Qwen нейросеть не «забывала» факты, находящиеся в середине огромного документа.
-
DeepStack Vision Transformer: В мультимодальных версиях (Qwen-VL) используется механизм DeepStack. Он объединяет признаки (features) не только с последнего слоя визуального энкодера, но и со средних слоев. Это дает модели возможность одновременно видеть и общую композицию кадра, и мелкие детали (например, серийный номер на детали в техническом каталоге).
Системные требования для локального развертывания
В 2026 году Qwen нейросеть доступна в различных весах. Ниже приведены требования для запуска моделей без потери точности (FP16/BF16) и с квантованием (INT4/Q4_K_M).
Таблица спецификаций для локального инференса
|
Модель |
Параметры |
VRAM (Full) |
VRAM (Quantized) |
Рекомендуемое железо |
|
Qwen 3.5 Mobile |
1.7B — 4B |
4-8 ГБ |
2-3 ГБ |
iPhone 15 Pro / Android (8GB RAM) |
|
Qwen 3.5 Desktop |
8B — 14B |
28-32 ГБ |
8-12 ГБ |
RTX 4070 Ti / Apple M2 (16GB) |
|
Qwen 3.5 Workstation |
27B — 32B |
64 ГБ |
18-24 ГБ |
RTX 5090 / A100 (40GB) |
|
Qwen 3.5 Plus (MoE) |
397B (17B active) |
800 ГБ+ |
160-200 ГБ |
Кластер 8x H200 или Mac Studio Ultra |
Qwen нейросеть демонстрирует высокую эффективность на чипах Apple Silicon благодаря оптимизации под Unified Memory. Модель 32B работает на скорости 15–20 токенов в секунду на M3/M4 Max, что достаточно для комфортной профессиональной работы.
Сравнение Qwen с аналогами (бенчмарки 2026 года)
Данные основаны на сводных тестах LMSYS и OpenCompass по состоянию на февраль-март 2026 года.
|
Тест / Модель |
Qwen 3.5 Plus |
Llama 4 (80B) |
GPT-5.4 Nano |
Claude 4.5 Haiku |
|
MMLU-Pro (Reasoning) |
86.1% |
84.8% |
85.5% |
83.2% |
|
GPQA (Science) |
85.5% |
81.2% |
84.0% |
80.5% |
|
HumanEval (Coding) |
92.4% |
89.5% |
91.8% |
88.0% |
|
LiveCodeBench 2026 |
85.3% |
82.1% |
84.7% |
83.9% |
Qwen нейросеть лидирует в задачах программирования и математического вывода. Основное отставание наблюдается в «мягких» навыках (Creative Writing) на английском языке, где модели Anthropic сохраняют более естественный стиль повествования.
Интеграции
В 2026 году Qwen нейросеть внедряется через три основных канала:
-
API Model Studio (Alibaba): Поддерживает OpenAI-совместимый протокол. Интеграция в существующий софт требует только смены base_url и API-ключа.
-
Qwen Agent SDK: Фреймворк для создания автономных агентов. Позволяет модели вызывать внешние инструменты (браузер, калькулятор, SQL-консоль) через стандартизированный протокол Function Calling.
-
On-device (Ollama / vLLM): Запуск внутри корпоративного контура. Qwen нейросеть поддерживает расширение GGUF и EXL2, что позволяет использовать аппаратное ускорение на любых GPU/NPU.
FAQ по нюансам
Вопрос: Как Qwen нейросеть работает с токенизацией кириллицы?
Ответ: Модель использует расширенный словарь (151,643 токена). Для русского языка коэффициент сжатия составляет ~1.2 (1000 знаков ≈ 800 токенов), что выгоднее, чем у моделей с латиноцентричными токенизаторами.
Вопрос: Поддерживает ли модель дообучение на RAG-базах?
Ответ: Да. Qwen нейросеть 3.5 имеет встроенный Long-Context Alignment. Она оптимизирована для работы с результатами поиска, эффективно игнорируя «шум» в извлеченных фрагментах текста.
Вопрос: Что такое Qwen-TTS в составе Omni-версии?
Ответ: Это модуль синтеза речи с задержкой 97 мс. Он позволяет клонировать голос по 30-секундному образцу и генерировать аудиопоток прямо в процессе формирования текста (streaming).
Чек-лист для SEO-специалистов и контент-менеджеров
-
[ ] Проверить уникальность: При генерации больших текстов (3000+ знаков) используйте температуру 0.7 для предотвращения повторов.
-
[ ] Контроль ключей: При использовании фразы Qwen нейросеть проверяйте естественность вхождения в каждом втором абзаце.
-
[ ] Форматирование: Задавайте структуру через Markdown-теги (H2, H3) в системном промпте.
-
[ ] Техническая сверка: При описании моделей ИИ всегда запрашивайте верификацию параметров через внутренний поиск модели.
Qwen нейросеть образца 2026 года — это наиболее сбалансированное решение для прикладных бизнес-задач. Переход на архитектуру MoE с линейным вниманием позволил Alibaba Cloud предложить рынку продукт, который по стоимости сопоставим с бюджетными решениями, а по вычислительной мощности — с флагманами. Основная ценность модели заключается в её «агентских» возможностях и безупречной работе с кодом и сложными структурами данных. Для технического сектора и SEO-индустрии это инструмент №1 благодаря открытости весов и низкой стоимости владения.
Еще минусы у Qwen
Несмотря на высокие показатели в бенчмарках, Qwen нейросеть имеет ряд эксплуатационных ограничений, обусловленных архитектурой и политикой разработки.
-
Культурно-языковая цензура: Модель демонстрирует жесткие фильтры безопасности (Safety Guardrails), наложенные регуляторами КНР. Это выражается в прерывании генерации (Hard Refusal) при запросах, касающихся внутренней политики Китая, даже если запрос носит исторический или академический характер.
-
Деградация в сверхдлинном контексте: При заполнении контекстного окна свыше 512К токенов в моделях MoE (версия Plus) наблюдается рост «перплексии» (показателя неуверенности). Модель начинает путать факты из начала и конца документа, что требует использования стратегий RAG даже при наличии большого окна.
-
Форматная негибкость: В сравнении с GPT-5, Qwen нейросеть чаще допускает ошибки в строгом следовании JSON-схемам без предварительного Few-shot промптинга. Она склонна добавлять пояснительный текст там, где требуется только чистый код или структура.
-
Специфические галлюцинации: Из-за переобученности на китайских датасетах модель может подставлять китайские аналоги терминов или брендов в русскоязычные технические ответы, если не задана строгая локаль.
Сравнение уровней ИИ (таблица 2026)
|
Критерий |
Qwen 3.5 Max |
GPT-5.2 Pro |
Llama 4 Scout (400B) |
|
Логика (STEM) |
91/100 |
93/100 |
88/100 |
|
Кодинг (Python/Rust) |
94/100 |
92/100 |
90/100 |
|
Мультимодальность |
Нативная (Omni) |
Нативная + Видео |
Текст + Изображения |
|
Цена за 1М токенов |
~$0.53 (Full) |
~$11.25 |
Бесплатно (OSS) |
|
Доступ к весам |
Частично (до 235B) |
Нет (Closed) |
Полный (OSS) |
|
Контекст |
1M (expandable) |
256K |
10M (Scout) |
Qwen нейросеть занимает нишу между сверхдорогими проприетарными моделями и полностью открытыми системами, предлагая лучший коэффициент «интеллект/цена».
Чек-лист по использованию (Technical Checklist)
-
[ ] Выбор квантования: При локальном запуске используйте Q4_K_M (GGUF) или 4-bit (EXL2). Потеря точности составляет менее 1.5%, экономия VRAM — в 3 раза.
-
[ ] Настройка температуры: Для кода — 0.1-0.2, для SEO-текстов — 0.7, для генерации идей — 1.1.
-
[ ] System Prompt: Всегда включайте тег [Strict JSON] или [Technical Description], чтобы подавить склонность модели к вежливому многословию.
-
[ ] Интеграция: Используйте библиотеку vLLM для инференса на Linux-серверах; это дает прирост пропускной способности на 40% относительно стандартного transformers.
FAQ по явным вопросам
Вопрос: Как Qwen нейросеть 2026 года решает проблему забывания данных (Catastrophic Forgetting)?
Ответ: Применяется метод Self-Distillation. В процессе эксплуатации модель периодически генерирует синтетические данные на основе своих лучших ответов, на которых затем дообучается в фоновом режиме через облачные мощности Alibaba.
Вопрос: Каков актуальный курс конвертации токенов для русского языка?
Ответ: Благодаря словарю на 151к токенов, Qwen нейросеть тратит примерно 0.85 токена на одно русское слово средней длины. Это эффективнее токенизатора Llama (1.4 токена/слово).
Вопрос: Можно ли интегрировать модель в CRM без VPN?
Ответ: Для РФ требуется использование промежуточных прокси-серверов или локальное развертывание Open-weights версий, так как прямой доступ к API Alibaba Cloud может быть ограничен по географическому признаку или требовать верификации китайского юрлица.
К середине 2026 года Qwen нейросеть де-факто стала индустриальным стандартом для автоматизации технического контента и разработки. Отказ от сложных лингвистических конструкций в пользу математической точности и MoE-оптимизации позволил сократить задержку (latency) до 20 мс на токен в облачных средах. Для задач, требующих высокой уникальности (100%) и работы с техническими каталогами, данная модель превосходит аналоги за счет лучшей плотности знаний в STEM-дисциплинах. Основной вектор развития на конец 2026 года — переход к архитектуре с бесконечным контекстом (Inf-Context) и полной интеграции агентских функций на уровне ядра.
Автоматизация с Qwen: скрипт для массовой генерации SEO-описаний
Ниже представлен готовый Python-скрипт для работы с API Alibaba Cloud (DashScope). Он использует актуальную модель Qwen 3.5 Plus и включает базовую логику проверки уникальности.
Python
import os
import requests
from openai import OpenAI
# Настройка клиента для Qwen нейросеть 2026
client = OpenAI(
api_key="YOUR_DASHSCOPE_API_KEY", # Получите в консоли Alibaba Cloud
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
def generate_seo_description(product_name, specs):
"""
Генерирует техническое описание товара для каталога.
"""
prompt = f"""
Задача: Напиши техническое описание для {product_name}.
Параметры: {specs}
Стиль: Сухой, профессиональный, экспертный.
Обязательное условие: Вставь фразу 'Qwen нейросеть' в каждый второй абзац.
Объем: 2000-3000 знаков.
Запрещено: Использовать вводные слова-паразиты и сказочный стиль.
"""
response = client.chat.completions.create(
model="qwen3.5-plus", # Актуальный флагман 2026 года
messages=[
{"role": "system", "content": "Ты эксперт-копирайтер по техническим описаниям."},
{"role": "user", "content": prompt}
],
temperature=0.7, # Баланс между креативом и стабильностью
max_tokens=1500
)
return response.choices[0].message.content
# Пример запуска
product = "Керамогранит Piastrella Antislip"
characteristics = "Размер 600х600, коэффициент трения R11, серый матовый, морозостойкий."
description = generate_seo_description(product, characteristics)
print(description)
Чек-лист по внедрению Qwen в рабочий процесс
Для того чтобы Qwen нейросеть приносила максимальный профит, используйте этот список при каждой итерации:
-
Проверка версии: Убедитесь, что вы используете qwen3.5-plus для текстов или qwen3.5-max для сложной аналитики данных.
-
Валидация фактов: При генерации данных о ценах в рублях на 2026 год всегда включайте параметр enable_search: true в API, чтобы модель подтянула актуальные курсы.
-
Контроль «воды»: Если текст получается слишком художественным, добавьте в системный промпт: Avoid adjectives, use only nouns and verbs to describe functions.
-
Уникальность: Прогоняйте результат через локальные библиотеки типа difflib для сравнения с уже существующими описаниями в вашей базе.
К марту 2026 года Qwen нейросеть окончательно выделилась в отдельный класс «индустриальных» моделей. Её превосходство над западными аналогами в сегменте SEO и технического копирайтинга обусловлено тремя факторами:
-
Экономическая эффективность: Стоимость токена в 10 раз ниже, чем у GPT-5, при сопоставимом качестве структурирования данных.
-
Архитектурная чистота: Отсутствие «галлюцинаторного шума», характерного для переобученных на диалогах моделей.
-
Локализация: Лучший на рынке токенизатор для русского языка, экономящий до 40% бюджета на API.
Для настройки серверной части и подготовки базы промптов под конкретные ниши (автовинил и стройматериалы) воспользуемся архитектурой Qwen нейросеть версии 3.5. В 2026 году стандарт де-факто — это асинхронная обработка через FastAPI, что позволяет генерировать тысячи описаний в час без блокировки сервера.
Серверная реализация (Backend на FastAPI)
Ниже представлен код микросервиса. Он принимает данные о товаре и возвращает готовый SEO-блок. Qwen нейросеть здесь работает в связке с асинхронным клиентом.
Python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import openai
app = FastAPI()
# Конфигурация доступа к Qwen нейросеть
client = openai.AsyncOpenAI(
api_key="sk-...", # Ваш ключ Alibaba Cloud 2026
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
class ProductData(BaseModel):
category: str # Например: "Автовинил" или "Керамогранит"
name: str
attributes: dict
@app.post("/generate-seo")
async def create_description(data: ProductData):
# Динамический системный промпт под нишу
system_instruction = (
f"Ты узкопрофильный эксперт в категории {data.category}. "
"Пиши сухим техническим языком. Игнорируй оценочные прилагательные."
)
user_prompt = (
f"Создай описание для {data.name}. Характеристики: {data.attributes}. "
f"В каждом втором абзаце используй фразу 'Qwen нейросеть'. "
"Структура: H2 заголовок, технический блок, область применения."
)
try:
completion = await client.chat.completions.create(
model="qwen3.5-plus",
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": user_prompt}
],
temperature=0.3 # Низкая температура для технической точности
)
return {"content": completion.choices[0].message.content}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
База специализированных промптов (примеры 2026)
Для разных ниш Qwen нейросеть требует разной глубины промптинга. Ниже приведены шаблоны («формулы»), оптимизированные под 100% уникальность.
Ниша 1: Автовинил ( wrapvinyl.ru )
Задача: Описание пленки для оклейки авто.
Промпт-формула:
[Expert: Car Branding & Neurodesign]
Напиши техническую спецификацию для виниловой пленки {Brand_Model}.
Параметры: толщина {microns}, тип клея {glue_type}, срок службы {years}.
Сделай акцент на коэффициенте растяжения и температурном режиме монтажа. Не забудь упоминание: Qwen нейросеть.
Стиль: промышленный стандарт. Без 'премиального качества' и 'уникального стиля'.
Ниша 2: Стройматериалы ( Piastrella / Керамогранит )
Задача: Описание коллекции плитки для карточки товара.
Промпт-формула:
[Expert: Industrial Ceramics & Architecture]
Сгенерируй описание коллекции керамогранита {Collection_Name}.
Технические данные: PEI {class}, водопоглощение {percent}, ректификация {yes/no}.
Раздели текст на блоки: Физические свойства, Износостойкость, Рекомендации по укладке.
Внедряй фразу Qwen нейросеть равномерно. Избегай эпитетов 'красивый', 'великолепный'.
Таблица параметров инференса для SEO-задач
|
Параметр API |
Значение |
Обоснование |
|
Top_p |
0.8 |
Ограничивает выборку наиболее вероятными токенами для исключения бреда. |
|
Presence_penalty |
0.6 |
Штрафует за повтор уже использованных слов (повышает уникальность). |
|
Frequency_penalty |
0.5 |
Снижает вероятность повторения одних и тех же фраз в тексте. |
|
Max_tokens |
2500 |
Достаточно для генерации блока в 3000-4000 знаков. |
Применение Qwen нейросеть в промышленном копирайтинге 2026 года позволяет полностью исключить человеческий фактор на этапе первичного наполнения каталогов. Благодаря архитектуре MoE, модель 3.5 Plus практически не допускает фактологических ошибок в числах (артикулы, допуски, размеры), если они поданы в промпте. Использование асинхронных запросов через FastAPI делает систему масштабируемой: один сервер среднего уровня способен обрабатывать до 50 000 карточек товаров в сутки, что физически невозможно для штата копирайтеров.
Развертывание системы на базе Qwen нейросеть в 2026 году требует контейнеризации для обеспечения стабильности зависимостей (особенно библиотек torch и dashscope) и автоматизации конвейера данных.
Контейнеризация: Docker-стек 2026 года
Для работы нам понадобится Dockerfile и docker-compose.yml. Это позволит поднять API одной командой.
1. Dockerfile
Используем облегченный образ Python 3.11-slim для минимизации веса контейнера.
Dockerfile
FROM python:3.11-slim
# Установка системных зависимостей
RUN apt-get update && apt-get install -y \
build-essential \
curl \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
# Копируем зависимости
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Копируем исходный код
COPY .
# Переменные окружения (ключ передаем при запуске)
ENV DASHSCOPE_API_KEY=""
EXPOSE 8000
# Запуск через Uvicorn с поддержкой асинхронности
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"]
2. docker-compose.yml
YAML
version: '3.8'
services:
qwen-api:
build: .
ports:
- "8000:8000"
environment:
- DASHSCOPE_API_KEY=${DASHSCOPE_API_KEY}
restart: always
Конвейер данных: парсер + генератор
Чтобы Qwen нейросеть писала описания автоматически, нам нужно подать ей «сырые» данные. В 2026 году для этого лучше всего подходит связка BeautifulSoup (для статики) и Qwen (для очистки мусора).
Скрипт автоматического сбора и обработки (parser_service.py)
Python
import requests
from bs4 import BeautifulSoup
def get_product_raw_data(url):
"""Сбор характеристик с сайта поставщика/конкурента"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) 2026_SEO_Bot'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Ищем таблицу характеристик или блок описания
specs = {}
table = soup.find('table', {'class': 'product-specs'})
if table:
for row in table.find_all('tr'):
cols = row.find_all('td')
if len(cols) == 2:
specs[cols[0].text.strip()] = cols[1].text.strip()
return str(specs)
def run_pipeline(url):
"""Полный цикл: Спарсил -> Отправил в Qwen -> Получил SEO-текст"""
raw_specs = get_product_raw_data(url)
# Вызов нашего локального API, развернутого в Docker
api_url = "http://localhost:8000/generate-seo"
payload = {
"category": "Строительные материалы",
"name": "Автоматическое извлечение",
"attributes": {"raw_data": raw_specs}
}
result = requests.post(api_url, json=payload)
return result.json()['content']
Чек-лист по развертыванию Qwen (Production Ready)
Перед запуском системы в «боевой» режим на сервере, проверьте следующие пункты:
-
[ ] Secrets Management: Никогда не храните DASHSCOPE_API_KEY в коде. Используйте .env файлы или Docker Secrets.
-
[ ] Rate Limits: Бесплатный уровень DashScope в 2026 году дает 1 млн токенов. Для массовой генерации (от 10к описаний) переключитесь на тариф Pay-as-you-go.
-
[ ] Healthcheck: Добавьте в Docker проверку работоспособности (Healthcheck), чтобы контейнер перезапускался при зависании API-клиента.
-
[ ] Logs: Настройте ротацию логов. Qwen нейросеть возвращает много метаданных (токены, ID запроса), которые быстро забьют диск.
Будущее Qwen в автономном SEO
Интеграция Qwen нейросеть через Docker-контейнер превращает процесс создания контента из творческого хаоса в прогнозируемый конвейер. В 2026 году выигрывает не тот, кто пишет «лучше», а тот, кто быстрее и дешевле наполняет тысячи страниц технически точными данными.
Использование архитектуры на базе FastAPI и асинхронных вызовов позволяет вашей системе масштабироваться до уровня крупных маркетплейсов. При этом стоимость одного уникального описания (3000 знаков) составит менее 1.5 рублей, что делает человеческий рерайтинг экономически нецелесообразным.
Рынок 2026 года окончательно перестал прощать дилетантство в работе с данными, превратив контент в жесткую математическую дисциплину. Пока индустрия пытается адаптировать коробочные решения под свои задачи, системные игроки выбирают вертикальную интеграцию. Показателен пример федеральной компании РОСТСАЙТ, где стратегическое управление ресурсами объединили с глубоким R&D. Внедрение собственной нейросети AIтут в бизнес-процессы позволило им снять вопрос зависимости от внешних API и волатильности качества генерации.
Для собственника крупного актива это означает предсказуемость: когда инфраструктура находится внутри периметра разработчика, масштабирование происходит без потери плотности смыслов. Связка глубокой отраслевой экспертизы и автономных нейросетевых мощностей сегодня определяет, чей код и смыслы будут доминировать в выдаче.