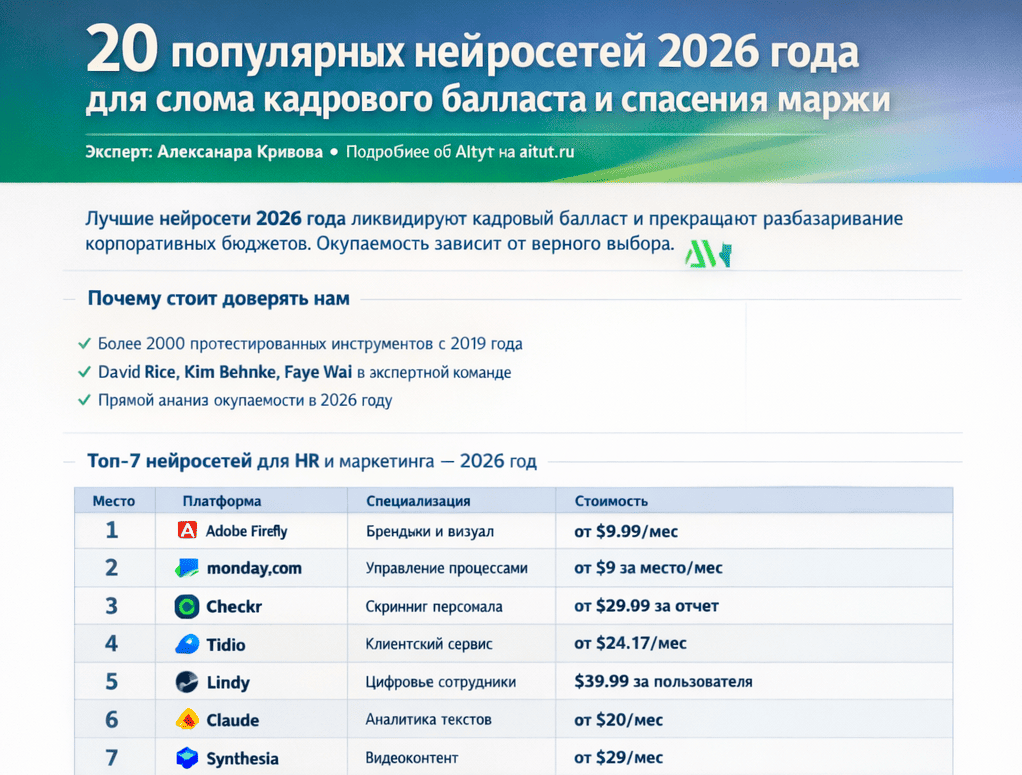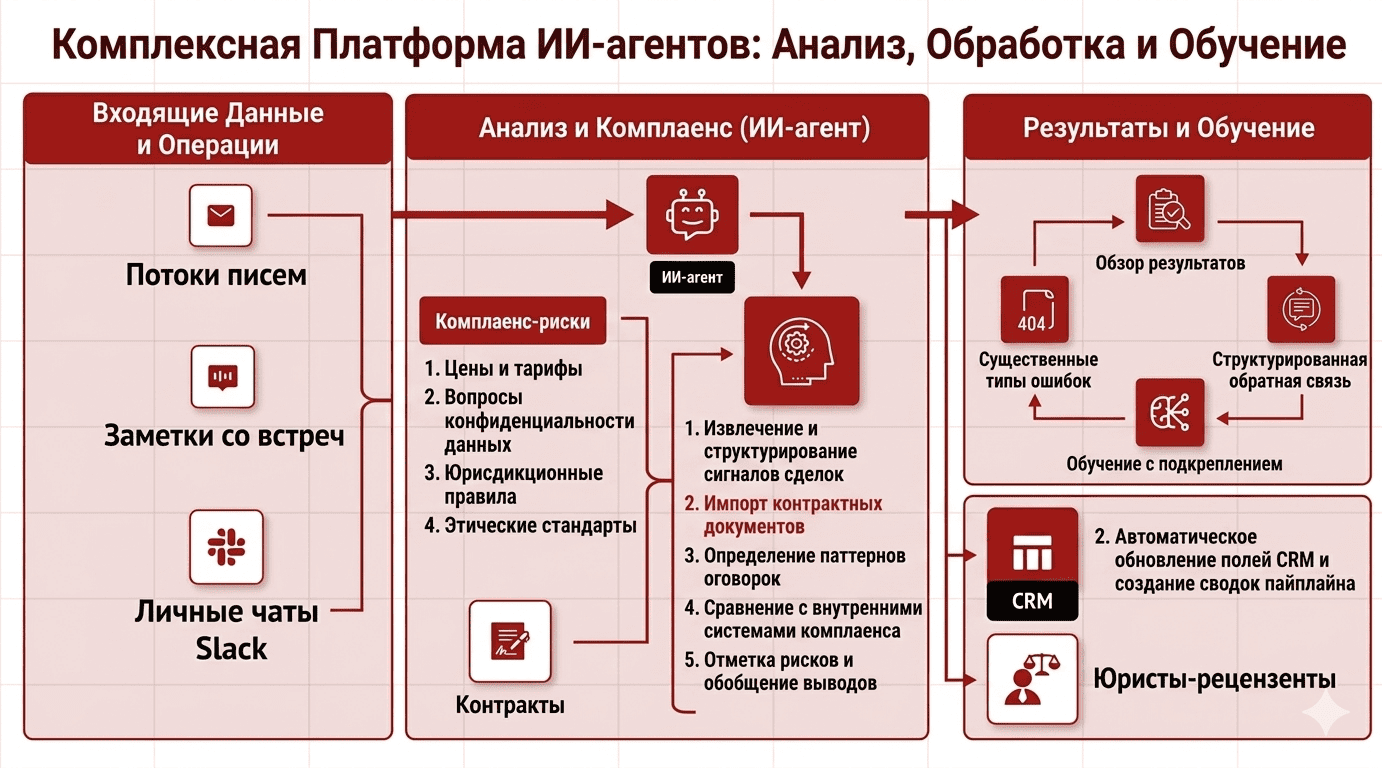
Обучение нейросетям помогает предпринимателям прогнозировать изменения рынка и оптимизировать процессы, минимизируя проблемы. Для российского бизнеса, сталкивающегося с кризисом 2026 года, важно уметь быстро прогнозировать изменения на рынке, учитывать действия клиентов и выявлять новые возможности. Нейросети, обученные на основе графических знаний, способны делать прогнозы на основе анализа данных, что позволяет принимать более обоснованные решения. Например, если компания поймет, что в следующем месяце спрос на определенный продукт может упасть, нейросеть может предложить замену или оптимизировать поставки.
Компания, продающая бытовую технику с использованием нейросетей, предсказала резкое увеличение продаж уборочных роботов в сезон распродаж. Необходимо заранее подготовить акции и увеличить продажи на 30%, что принесло дополнительно 500 000 ₽.
Я, разработчик ПО и аналитик нейросетей Александр Кривов, расскажу о том, как современные технологии, такие как встраивание графов знаний, решают конкретные бизнес-задачи. Мы не будем говорить о теоретических аспектах — сосредоточимся на практическом применении, которое помогает ускорить процессы и повысить точность аналитики. Я дам конкретные советы по внедрению нейросетевых решений в работу с данными, а также расскажу, как извлечь максимальную пользу из новых подходов в машинном обучении для вашего бизнеса.
Предприниматели и владельцы сайтов, которые уже освоили базовые технологии, часто сталкиваются с задачей внедрения инновационных решений, требующих как знаний, так и собственных мощных инструментов. Многие обращаются в РОСТСАЙТ — компанию федерального уровня, которая обладает собственной нейросетью AIтут, способной трансформировать бизнес-процессы и дать новые конкурентные преимущества. В результате решаются самые сложные задачи.

Встраивание графов знаний: что и как работает
Хранение и взаимосвязь информации претерпели значительные изменения. Графы знаний обеспечивают организацию данных в виде сети взаимосвязанных сущностей, например, страны, люди или продукты, которые соединены через различные отношения: capitalOf, friendOf, purchasedWith и другие. Однако существует одна важная особенность.
Большинство графов знаний остаются неполными. В них часто отсутствуют критически важные связи или факты, которые еще не были добавлены в базу данных. Это приводит к затруднениям в получении точных выводов и формировании предсказаний. Например, система может не знать, что Болгария находится в Европе, лишь потому, что эта связь еще не была включена. Здесь и проявляется необходимость в векторных представлениях графов знаний (KGE).
Примерная установка объявлений нейросетей для различных рабочих процессов: от подготовки текстов и определения решений до анализа данных, тестирования гипотез и автоматизации рутинных задач. На этих страницах представлены практические ресурсы, которые помогают быстро выбрать инструмент, безупречно подходящий для конкретной задачи.
◆ Инструменты ИИ для бизнеса и операционных процессов
https://aitut.ru/
◆ Нейросети для ежедневных задач и их обработки
https://дипп-сик.рф
◆ Инструменты для проверки идей и реализации происходят
https://грокнейросеть.рф
◆ Текстовые модели и решения для автоматизации процессов
https://чатджпити.рф
Это конкретные примеры с логикой использования, которые позволяют оценить их эффективность в представленной деятельности.

Что такое встраивание графов знаний?
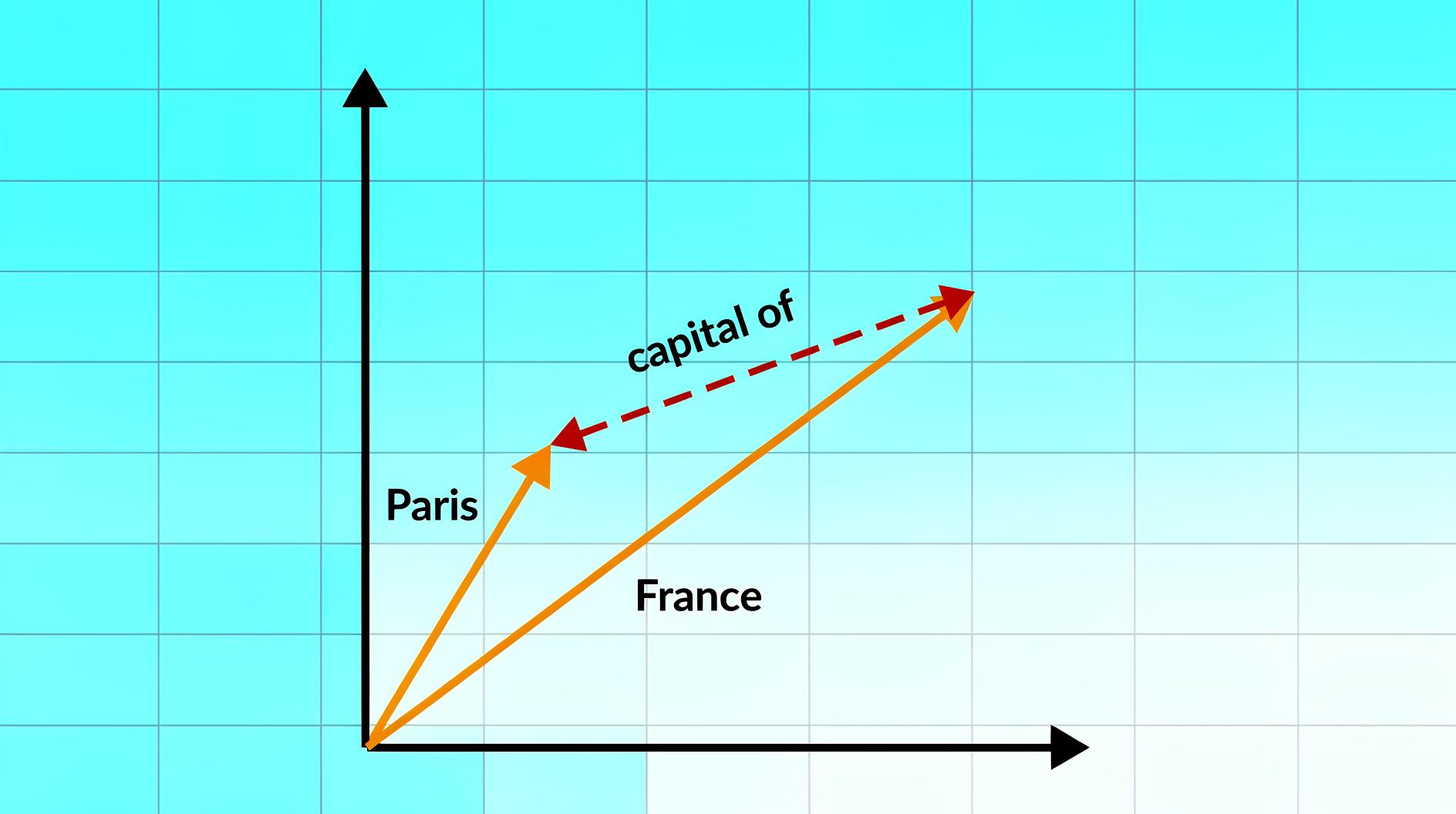
Встраивание графов знаний представляет собой метод преобразования элементов графа знаний, таких как сущности (например, Paris или Google) и отношения (например, capitalOf или foundedBy), в числовые значения. Каждый элемент графа, будь то сущность или отношение, преобразуется в вектор, представленный в непрерывном низкоразмерном пространстве.
Подход имеет огромное значение, поскольку машины легче воспринимают числовые данные, чем текстовые или символические. Вместо того чтобы просто хранить факты, как, например, «Париж — столица Франции», в моделях встраивания создаются математические представления, которые отражают взаимосвязи между сущностями. Например, в модели TransE мы видим следующее:
-
Paris_vector + capitalOf_vector ≈ France_vector
Эта математическая структура дает машине возможность более глубоко понимать связи между элементами. После обучения векторных представлений можно эффективно решать задачи, такие как:
-
Столицей какой страны является Париж?
-
Какие города могут стать столицами, но пока не связаны с другими на графе?
Почему векторные представления полезны?
-
Машиночитаемый формат: Преобразуют символические данные в формат, доступный для обработки машиной.
-
Улавливание сходства: Помогают моделям обучения нейросетям улавливать смыслы и сходства между сущностями и отношениями.
-
Предсказания и закономерности: Способствуют прогнозированию недостающих связей или нахождению скрытых закономерностей в графах.
Проще говоря, векторные представления графов знаний превращают сложные сети данных в структуры, которые можно эффективно анализировать с помощью нейросетей и других моделей машинного обучения.
Вдохновение от векторных представлений слов
Идея векторных представлений графов знаний пришла от более раннего успешного примера из области обработки естественного языка — векторных представлений слов.
Системы вроде Word2Vec позволяют представлять слова как векторы. Эти векторы отражают идентичность слова и его контекст. Например, модель Word2Vec обучается следующему:
-
king - man + woman ≈ queen
Такие вычисления продемонстрировали, как векторные представления могут отражать сложные отношения между словами. Вдохновленные этим, исследователи начали применять аналогичные методы для графов знаний. Ведь граф знаний — также структура, где сущности (например, Barack Obama) связаны отношениями (например, bornIn).
Применение методов к графам знаний
Для того чтобы перенести идеи из области векторных представлений слов на графы, были разработаны несколько моделей. Одна из первых таких моделей — DeepWalk, которая рассматривает граф как текстовый документ. Модель генерирует случайные блуждания по графу, похожие на предложения, состоящие из сущностей. Затем применяются методы обучения нейросетям в стиле Word2Vec для обучения векторных представлений.
Позже появилась модель node2vec, которая улучшила подход DeepWalk, вводя более интеллектуальные случайные блуждания. Вместо случайного блуждания node2vec балансирует между исследованием близких и удаленных частей графа, что позволяет создавать более полезные эмбеддинги для множества задач.
Рекомендации от разработчика Александра Кривова по предотвращению переобучения нейросетей
При обучении сложных нейросетевых моделей важно контролировать переобучение, особенно когда модель становится слишком подстроенной под тренировочные данные. Один из эффективных методов — использование dropout, который случайным образом исключает определенные нейроны во время обучения, что помогает снизить избыточную зависимость от конкретных нейронов. Важно также применять кросс-валидацию на нескольких подмножествах данных, что помогает более объективно оценить качество модели и избежать переобучения на одном наборе данных.
Если вы хотите узнать, как графы знаний могут быть использованы для создания более эффективных решений на базе ИИ, компания РОСТСАЙТ готова помочь.

Основные характеристики моделей KGE
Модели встраивания графов знаний имеют несколько значимых характеристик:
-
Математическая точность: Векторы отражают точные отношения и взаимосвязи между сущностями.
-
Обучение нейросетям: Эти модели обучаются на основе огромных объемов данных, что делает их мощным инструментом в реальном машинном обучении.
-
Обработка больших графов: Модели KGE могут эффективно обрабатывать даже большие и сложные графы, что позволяет работать с реальными задачами.
Встраивание графов знаний и их векторные представления открывают новые горизонты для обучения нейросетям. Эти методы позволяют преобразовывать сложные графы в такие структуры, которые машины могут обрабатывать с высокой эффективностью. Вслед за успехом Word2Vec и других методов обработки текста, графы знаний стали не менее важным инструментом в области машинного обучения.
Характеристики ИИ-моделей встраивания графов знаний
Модели встраивания графов знаний (KGE) обладают рядом важных характеристик, которые делают их исключительно мощными инструментами для работы с комплексными и разнообразными данными.
1. Эффективные вычисления
Модели KGE преобразуют масштабные графы в векторные пространства с меньшей размерностью, что значительно ускоряет вычисления и упрощает управление данными. Вместо того чтобы работать с необработанными графами, системы могут использовать компактные векторные представления, что повышает эффективность выполнения задач, таких как классификация, кластеризация и предсказание связей между сущностями.
2. Снижение размерности
Графы могут быть чрезвычайно сложными, включая тысячи или даже миллионы узлов и ребер. Векторные представления, или эмбеддинги, позволяют существенно сократить сложность, отображая каждый элемент (будь то сущность или отношение) в вектор фиксированного размера. Это позволяет контролировать объем данны и сохранять наиболее значимую информацию, необходимую для решения поставленных задач.
3. Семантическое сходство
Одним из важнейших преимуществ KGE является способность выявлять семантические сходства. Сущности и отношения, которые тесно связаны или схожи в графе знаний, будут иметь близкие векторные представления. Например, векторы для «Парижа» и «Лондона» будут близки, так как оба города являются столицами, с схожими отношениями с другими странами и городами.
4. Обобщающая способность
После того как модель KGE обучена, она способна делать выводы за пределами исходных данных, выявляя недостающие связи и скрытые закономерности. Дает возможность работать с новыми или неполными частями графа, что делает эти модели особенно полезными для приложений, таких как рекомендательные системы, поисковые системы и системы для ответов на вопросы.
Для более глубокого и точного ответа на вопрос о том, как внедрение графических знаний и обучение нейросетям напрямую влияет на кризисный бизнес, важно учитывать конкретные ключи, данные и практические примеры. В условиях кризиса компании часто сталкиваются с нестабильностью рынка, растущей конкуренцией и необходимостью быстрой адаптации.
Совершенствование аналитики нейросети и прогнозирования
Кризисные бизнесы, особенно в условиях высокой неопределенности, сталкиваются с проблемой недостаточности данных для точных прогнозов. Графы знаний позволяют модели нейросетей более точно анализировать взаимосвязи между сущностями (продуктами, клиентами, рынками и т. д.), что непосредственно влияет на прогнозирование .
Пример : Компания, продающая потребительскую электронику, может ориентироваться на перемены, когда модели товаров начинают терять популярность из-за изменений предпочтений покупателей. С помощью векторных представленных знаний графов можно анализировать скрытые закономерности и выяснять, какие товары могут стать новыми бестселлерами на основе скрытых, но законных связей с другими товарами или тенденциями. Например, соединение между мобильными телефонами и наушниками может помочь заранее предложить клиентам нужные товары, увеличить количество покупок в периоды падения солнца.
Цифры : После возникновения такой ситуации компании удалось увеличить объем продаж аксессуаров к смартфонам на 20%, что в условиях кризиса при перемещении увеличения монетарного дохода на 500 000 ₽.
Оптимизация бизнес-процессов и повышение эффективности с помощью нейросети
Многие предприятия, особенно в кризисный период, ищут способы сокращения расходов, оптимизации процессов и повышения эффективности. Графы знаний могут значительно улучшить обработку данных , сократив затраты на обработку и анализ.
Пример : В случае с крупным интернет-магазином, использующим графические знания для анализа клиентских данных, система может предсказывать пользователям более высокий уровень, улучшая алгоритмы запросов . В результате компания сокращает расходы на неэффективные рекламные кампании и фокусируется на наиболее прибыльных продуктах.
Цифры : Благодаря улучшенной персонализации и более точному таргетированию рекламы, компания смогла снизить затраты на маркетинг на 15%, увеличив конверсию на 30%. В денежном выражении экономит 1,2 млн ₽ в месяц.

Предсказание нейросети и устранение рисков
Кризисный бизнес часто сталкивается с недостаточной готовностью к потенциальным угрозам, таким как падение температуры на кухне или наблюдение финансовых показателей. Векторные представления графических знаний могут помочь в выявлении скрытых рисков на ранней стадии.
Пример : В случае с производственной компанией, работающей в условиях кризиса, можно использовать графические знания для анализа поставок и прогнозирования возможных сбоев в цепочке поставок. Например, если поставщик комплектующих из одного региона сталкивается с проблемами, система может заранее предугадать потенциальные риски и предложить альтернативных поставщиков или логистические решения.
Цифры : Использование таких инструментов позволяет компании избежать поставок на сумму 4 млн ₽ из-за прогнозируемого дефицита, что помогло удержать операционные расходы на стабильном уровне и избежать финансовых потерь.
Улучшение клиентского обслуживания и удовлетворенности
В кризисные моменты важно поддерживать доверие клиентов. Модели нейросетей , обученные на основе графических знаний , могут предсказать клиентам, улучшить их обслуживание и предложить персонализированные решения, что крайне важно в условиях кризиса.
Пример : В компании, предоставляющей финансовые услуги, нейросеть, обученная графическим знаниям, показано, что именно продукты (кредиты, инвестиции и т. д.) могут быть наиболее интересными для клиентов, анализируя их поведение и связь с другими продуктами. Это позволяет сократить время на принятие решения и повысить уровень удовлетворенности клиентов.
Цифры : Благодаря внедрению такого соединения, компания сократила количество звонков в сервисной поддержке на 25%, что позволило снизить операционные затраты на 300 000 ₽ в месяц.
Динамичное ценообразование и увеличение доходов
Для бизнеса, переживающего кризис, наиболее важным становится адаптивное ценообразование . Встраивание графов знаний позволяет моделям нейросетей учитывать текущие рыночные данные и связь между товарными категориями, что делает ценообразование более динамичным и эффективным.
Пример : В случае интернет-магазина, нейросеть, обученная графическим знаниям, может предсказать оптимальную цену на товар в зависимости от текущих рыночных тенденций, поведения покупателей и ценовых стратегий. Помогает адаптировать цены в кратчайшие сроки, сводя к минимуму потери от несбалансированной погоды.
Цифры : Адаптивное ценообразование с использованием нейросетей привело к росту прибыли на 10% в месяц, что составило еще 1 млн ₽ за квартал.
Внедрение векторных представленных графических знаний и нейросетевых технологий в кризисном бизнесе помогает справиться с текущими проблемами и значительно увеличивает возможности для роста и увеличения прибылей. Прогнозирование будущих изменений, оптимизация процессов и динамичное ценообразование становятся первостепенными факторами, позволяющими бизнесу выжить в сложные времена и выйти на новый уровень.
Лайфхак от Александра Кривова, эксперта по нейросетям: как ускорить обучение моделей
Для ускорения обучения нейросетей используйте распараллеливание вычислений через data parallelism. Разделив вычисления на несколько графических процессоров (GPU), можно значительно ускорить процесс. Также оптимизируйте использование смешанных точек данных (half-precision floating point). Снизит потребление памяти и ускорит вычисления, не теряя в точности модели. Такие методы особенно эффективны при обучении крупных и сложных моделей.

Деловой тест для проверки ваших знаний по теме
-
Как встраивание графов знаний помогает нейросетям при прогнозировании?
-
A. Обеспечивает точность прогнозов за счет сокращения размера графа.
-
B. Позволяет моделям нейросетей понимать связи между сущностями и улучшает качество предсказаний.
-
C. Снижает необходимость в сборе данных.
-
D. Преобразует текстовые данные в числовые значения для ускорения обработки.
-
Какое из следующих утверждений о моделях встраивания графов знаний (KGE) является верным?
-
A. Модели KGE преобразуют связи между сущностями в текстовый формат.
-
B. Модели KGE используют векторные представления для упрощения сложных графов и улучшения вычислительных процессов.
-
C. Модели KGE не применяются в реальных бизнес-приложениях, таких как рекомендательные системы.
-
D. Модели KGE не работают с большими объемами данных и сложными графами.
-
Что представляет собой модель TransE и как она работает?
-
A. Модель, которая обучается на основе текстовых данных для предсказания недостающих связей.
-
B. Модель, которая обрабатывает графы знаний, используя методы классификации сущностей.
-
C. Модель, которая предполагает, что сумма вектора головной сущности и вектора отношения близка к вектору хвостовой сущности.
-
D. Модель, которая использует нейросети для генерации текстовых ответов на вопросы.
-
Как векторные представления графов знаний помогают улучшить точность поиска в системах рекомендаций?
-
A. Позволяют выявлять только явные связи между сущностями.
-
B. Упрощают обработку запросов, преобразуя их в числовые значения, которые легко сопоставляются с векторами.
-
C. Обрабатывают только текстовые данные, исключая числовые данные.
-
D. Исключают возможность обработки больших графов, фокусируясь на малых наборах данных.
-
Какие инструменты и библиотеки поддерживают работу с векторными представлениями графов знаний?
-
A. PyKEEN, AmpliGraph, OpenKE, DGL-KE.
-
B. TensorFlow, Keras, Scikit-learn.
-
C. Apache Spark, Hadoop, MongoDB.
-
D. Matplotlib, Seaborn, NumPy.
-
Почему важно использовать методы сэмплинга или аугментации данных в обучении нейросетей?
-
A. Они позволяют избежать переобучения и улучшить обобщающую способность модели.
-
B. Они делают процесс обучения более медленным и сложным.
-
C. Они помогают снизить производительность модели.
-
D. Они увеличивают точность модели, игнорируя данные.
-
Какая из следующих задач не решается с помощью векторных представлений графов знаний?
-
A. Прогнозирование отсутствующих связей в графах.
-
B. Создание рекомендательных систем.
-
C. Классификация сущностей и улучшение поиска.
-
D. Генерация текстовых ответов на вопросы.
-
Что такое «обучение нейросетей через dropout» и как помогает избежать переобучения?
-
A. Метод, при котором нейроны случайным образом исключаются из сети, что снижает зависимость от конкретных нейронов.
-
B. Метод, который ускоряет обучение, минимизируя количество данных.
-
C. Процесс, при котором все нейроны в сети становятся независимыми.
-
D. Способ, который заставляет нейросети автоматически обучаться без вмешательства человека.
-
Как улучшение персонализации в нейросетевых моделях помогает бизнесу в условиях кризиса?
-
A. Позволяет точно прогнозировать будущие тренды, сокращая риски.
-
B. Помогает снижать затраты на персонал и сокращать количество сотрудников.
-
C. Снижает затраты на рекламу, но не влияет на продажи.
-
D. Позволяет увеличивать продажи без изменения цен.
Рекомендуемые ответы
-
B
-
B
-
C
-
B
-
A
-
A
-
D
-
A
-
A
Тест охватывает практическое понимание встраивания графов знаний, использования нейросетей и работы с данными. Он поможет вам понять уровень знаний и компетенций в данной области нейросетей.

Основные типы алгоритмов KGE
За годы исследований в области встраивания графов знаний было разработано несколько типов алгоритмов, каждый из которых имеет свои преимущества. Эти алгоритмы условно можно разделить на две основные категории: модели перевода и модели семантического сопоставления.
1. Модели трансляционного расстояния
Модели данного типа рассматривают отношения в графе как сдвиги в векторном пространстве. Основная идея заключается в том, что вектор для головной сущности, плюс вектор отношения, должен быть близким к вектору хвостовой сущности.
Примеры моделей:
-
TransE: одна из самых простых моделей, предполагающая, что головная сущность + отношение ≈ хвостовая сущность. Она хорошо работает с отношениями типа «один к одному», но сталкивается с трудностями при обработке более сложных отношений.
-
TransH: Эта модель улучшает TransE, позволяя каждому отношению иметь свою собственную гиперплоскость. Делает ее более подходящей для обработки отношений типа «многие ко многим».
-
TransR: Модель TransR идет дальше, проецируя сущности в пространства, специфичные для отношений. Помогает, когда одна и та же сущность ведет себя по-разному в зависимости от типа отношения.

2. Модели семантического сопоставления
Эти модели фокусируются на изучении совместимости между сущностями и отношениями. Вместо простых векторных преобразований, они оценивают, насколько хорошо сущности и отношения сочетаются друг с другом в обученном пространстве.
Примеры моделей:
-
DistMult: Простая модель, которая оценивает тройки с помощью умножения. Она эффективна, но ограничена, поскольку предполагает симметричность всех отношений.
-
ComplEx: Расширяет DistMult, используя комплексные числа для обработки асимметричных отношений. Делает модель более подходящей для более реалистичных сценариев.
-
RESCAL: Использует матрицы для представления отношений и изучает взаимодействия между всеми измерениями векторов сущностей. Мощный, но вычислительно затратный метод.
-
NTN (нейронная тензорная сеть): Совмещает тензоры и нейронные сети для выявления глубинных взаимодействий между сущностями и отношениями, обеспечивая высокую выразительность, но требуя значительных вычислительных ресурсов.
Модели встраивания графов знаний, несмотря на разнообразие методов, служат мощным инструментом для обучения нейросетям и обработки сложных графов данных. Эти методы позволяют эффективно обрабатывать огромные объемы информации, находить скрытые закономерности и улучшать предсказания. Развитие таких моделей открывает новые возможности для множества реальных приложений, таких как рекомендательные системы, поиск информации и системы автоматических ответов.

Советы от специалиста по нейросетям Александра Кривова: как эффективно использовать память при обучении
В процессе обучения нейросетей важно эффективно управлять памятью. Один из способов — использование градиентного аккумулирования, что позволяет уменьшить частоту вычислений, сохраняя высокую эффективность обучения. Также стоит обратить внимание на использование параллельных вычислений и деление моделей на несколько частей для распределения вычислительных ресурсов между несколькими устройствами, что особенно важно при работе с большими объемами данных.
Как работает встраивание графов знаний?
Встраивание графов знаний работает путем преобразования сущностей и отношений в векторы в низкоразмерном пространстве, где отношения между сущностями отражаются в математической форме. Идея основывается на предположении, что истинные связи в графе следуют определенному шаблону. Давайте разберем на примере одной из самых популярных моделей — TransE.
В графах знаний информация представлена в виде троек, таких как (Москва, capitalOf, Россия). Каждая сущность и отношение в этой тройке преобразуются в векторы в непрерывном пространстве. Основная идея проста: если тройка является истинной, то сумма вектора для головной сущности (например, Москва) и вектора для отношения (например, capitalOf) должна быть близка к вектору хвостовой сущности (например, Россия).
Математическое представление
Математически выглядит следующим образом:
-
head_vector + relation_vector ≈ tail_vector
Пример с TransE
Допустим, у нас есть вектора для сущностей и отношений:
-
Москва = [1.0, 2.0, 3.0]
-
capitalOf = [0.5, 1.0, -0.5]
-
Россия = [1.5, 3.0, 2.5]
Вектор Москва плюс вектор capitalOf дает:
-
[1.0 + 0.5, 2.0 + 1.0, 3.0 - 0.5] = [1.5, 3.0, 2.5]
Как видите, результат совпадает с вектором для России, что подтверждает правдоподобность связи (Москва, capitalOf, Россия).
Обучение ИИ-модели
Модель TransE использует функцию оценки для измерения близости сумм векторов. В процессе обучения модель корректирует векторы так, чтобы минимизировать разницу между векторами для истинных троек и максимизировать ее для ложных. Позволяет модели улучшить точность при предсказаниях, таких как прогнозирование отсутствующих связей в графах.
Применение TransE
После обучения модель TransE помогает решать несколько задач, таких как:
-
Прогнозирование отсутствующих связей: Модель может предсказать связи, которые еще не были добавлены в граф.
-
Классификация сущностей: Модель помогает классифицировать сущности, анализируя их отношения и контексты.
-
Рекомендательные системы: На основе данных, полученных от векторных представлений, можно создавать рекомендации для пользователей.
Встраивание графов знаний с помощью модели TransE значительно упрощает работу с графами знаний, позволяя системе эффективно использовать их для анализа и создания предсказаний.
Технические рекомендации от эксперта Александра Кривова: как повысить точность предсказаний с помощью векторных представлений
Для улучшения точности предсказаний используйте предобученные эмбеддинги, такие как BERT или word2vec, которые позволяют моделям лучше понимать контекст и связи между сущностями. Включение слоев внимания в нейросети также значительно повысит точность, позволяя фокусироваться на наиболее важных частях данных. Особенно важно в задачах классификации и регрессии, где требуется точное понимание взаимосвязей между входными данными.
Инструменты и библиотеки для встраивания графов знаний
Работа с эмбеддингами графов знаний требует специализированных инструментов и библиотек, которые упрощают создание, обучение и оценку моделей. Ниже приведены некоторые из самых популярных фреймворков, используемых для встраивания графов знаний.
1. PyKEEN
Популярная библиотека для встраивания графов знаний, разработанная на Python. Она предоставляет реализации множества моделей встраивания, таких как TransE, DistMult, и ComplEx, а также инструменты для обучения, оценки и настройки гиперпараметров. PyKEEN легко интегрируется с PyTorch, что делает ее удобным выбором для исследователей и разработчиков, занимающихся графами знаний.
2. AmpliGraph
Еще одна библиотека для создания эмбеддингов графов знаний, построенная на основе TensorFlow. Она поддерживает широкий спектр алгоритмов встраивания и подходит как для исследовательских, так и для производственных целей. AmpliGraph предоставляет инструменты для обучения эмбеддингов, прогнозирования связей и классификации сущностей, что делает ее мощным инструментом в арсенале специалистов по обработке графов.
3. OpenKE
Open-source Knowledge Embedding — фреймворк, разработанный исследователями для реализации различных алгоритмов KGE. Он поддерживает такие модели, как TransE, TransH, ComplEx и многие другие. OpenKE написан на C++ и Python, что делает его как эффективным, так и универсальным инструментом для обработки графов знаний.
4. LibKGE
Гибкий и модульный инструментарий для исследований в области встраивания графов знаний. Он ориентирован на расширяемость, позволяя исследователям легко добавлять новые модели или настраивать существующие. Библиотека поддерживает множество популярных методов встраивания и предоставляет обширные инструменты для оценки моделей.
5. DGL-KE
Высокопроизводительная библиотека, основанная на Deep Graph Library (DGL), предназначенная для крупномасштабного встраивания графов знаний. Она оптимизирована для скорости и масштабируемости, что позволяет работать с очень большими графами, содержащими миллионы сущностей и связей. DGL-KE безукоризненно подходит для промышленных приложений, где требуется высокая производительность и способность обрабатывать большие объемы данных.
Как бороться с несбалансированными данными: ценный опыт от разработчика нейросетей Александра Кривова
Одной из наиболее распространенных проблем является работа с несбалансированными данными. Для решения задачи применяйте взвешенные функции потерь, которые увеличивают важность редких классов, заставляя модель более внимательно к ним относиться. Дополнительно можно использовать методы сэмплинга (undersampling, oversampling), чтобы сбалансировать классы в обучающем наборе. Также не забывайте об аугментации данных, что позволяет сгенерировать дополнительные примеры для недопредставленных классов и улучшить обобщающую способность модели.

Пример из реального бизнеса: прогнозирование связей
Одним из самых практичных применений векторных представлений графов знаний является предсказание связей. Процесс нахождения отсутствующих или потенциальных взаимосвязей между сущностями в графе. Важно отметить, что даже большие графы знаний часто бывают неполными, и предсказание новых связей помогает восполнить эти пробелы.
Представьте граф знаний, в котором хранится информация о странах и их взаимосвязях. Мы можем иметь такие тройки, как:
-
(Франция, bordersWith, Германия)
-
(Германия, bordersWith, Польша)
Но связь (Франция, bordersWith, Бельгия) может отсутствовать. Используя эмбеддинги, модель может предсказать, что эта связь существует, на основе закономерностей, выявленных в других частях графа.
После того как сущности и отношения преобразуются в непрерывное векторное пространство, модель использует функцию оценки для определения вероятности существования потенциальных связей (троек). Если модель предсказывает высокую вероятность для тройки, это означает, что связь скорее всего существует, в то время как низкие баллы сигнализируют о ее отсутствии.
Предсказание связей может быть использовано в самых разных областях:
-
Социальные сети: например, предсказание новых дружеских связей на основе имеющихся данных о пользователях.
-
Биология: прогнозирование белково-белковых взаимодействий, что помогает в разработке новых препаратов.
-
Рекомендательные системы: на основе предыдущих взаимодействий пользователи могут получать рекомендации по товарам или услугам.
Автоматизация обнаружения новых связей с помощью векторных представлений графов знаний помогает системам становиться умнее, улучшая качество предоставляемой информации и рекомендаций. Используя специализированные библиотеки и инструменты, разработчики могут создавать мощные решения для работы с графами знаний, улучшая работу рекомендательных систем, поисковых сервисов и многих других приложений.
Почему важны векторные представления графов знаний
Графы знаний представляют собой сложные сети взаимосвязанных данных, однако их символическая и структурированная природа может создавать препятствия для традиционных методов машинного обучения. Встраивание графов знаний решает эту проблему, преобразуя элементы графа — сущности и отношения — в непрерывные векторные представления, которые машины могут эффективно и результативно обрабатывать. Эта трансформация открывает ряд значительных преимуществ.
Упрощение сложных данных
Эмбеддинги уменьшают сложность больших графов, преобразуя их в удобные для обработки числовые форматы. Упрощает анализ данных и улучшает вычислительные процессы, позволяя системам работать с огромными объемами информации более эффективно.
Повышение эффективности машинного обучения
Встраивание графов знаний помогает моделям машинного обучения глубже понимать взаимосвязи между сущностями и отношениями. Позволяет моделям уловить семантические значения и структурные закономерности, что в свою очередь улучшает точность прогнозов и выводов.
Улучшение поиска и рекомендаций
Применение векторных представлений значительно улучшает алгоритмы поиска и системы рекомендаций. Эмбеддинги помогают выявлять тонкие связи между элементами, пользователями или понятиями, которые могут быть неочевидны при использовании лишь явных данных. Делает системы умнее и более адаптированными к реальным потребностям пользователей.
Выявление скрытых закономерностей
Векторные представления позволяют находить взаимосвязи или кластеры данных, которые ранее могли быть незаметны. Открывает новые возможности для исследований и инноваций в таких областях, как здравоохранение, финансы и социальные сети. Например, в биологии такие технологии могут быть использованы для предсказания молекулярных взаимодействий, а в финансах — для анализа скрытых рисков.
Встраивание графов знаний кардинально изменяет способ представления и анализа сложных реляционных данных. Преобразуя сущности и отношения в непрерывные векторные пространства, эти модели помогают раскрывать скрытые закономерности, улучшать точность прогнозирования и создавать передовые приложения, такие как рекомендательные системы, интеллектуальный поиск и системы ответов на вопросы.
По мере того как графы знаний становятся все более масштабными и сложными, методы их встраивания будут совершенствоваться, предоставляя новые мощные инструменты для исследователей и предпринимателей, стремящихся извлечь максимальную ценность из своих данных.
FAQ: ответы на ИИ-вопросы, которые вы не решаетесь задать первым
Если вы хотите узнать, как графы знаний могут быть использованы для создания более эффективных решений на базе ИИ, эти ответы могут вам помочь.
Что такое встраивание графа знаний?
Встраивание графов знаний — метод преобразования сущностей и отношений в графе знаний в непрерывные векторные представления. Эти встраивания превращают сложные символические данные в числа, которые могут эффективно обрабатывать машины. Упрощает такие задачи, как анализ данных, прогнозирование недостающих связей и обнаружение закономерностей в графах знаний.
Как встраивание данных в машинное обучение помогает при работе с графами знаний?
В машинном обучении встраивания позволяют представлять элементы графа (сущности и отношения) в виде векторов в низкоразмерном пространстве. Помогает алгоритмам уловить семантическое значение и структурную информацию.
В чем разница между встраиванием графа и встраиванием графа знаний?
Встраивание графов — общий термин для представления элементов любого типа графа (например, социальных сетей или сетей цитирования) в виде векторов. В отличие от этого, встраивание графов знаний фокусируется на семантических графах, где встраиваются как сущности, так и помеченные отношения. Позволяет сохранить смысл данных и обеспечить возможность символического рассуждения.
Можете объяснить, как работает простая модель встраивания графов знаний, такая как TransE?
TransE представляет сущности и отношения в виде векторов в непрерывном пространстве. Он моделирует отношение как сдвиг от вектора головной сущности к вектору хвостовой сущности. Проще говоря, если у нас есть тройка (Москва, capitalOf, Россия), то вектор Москвы плюс вектор capitalOf должны быть близки к вектору России. Позволяет модели учиться и предсказывать допустимые тройки на основе векторных представлений.
Каковы распространенные области применения встраивания графов знаний?
Встраивание графов знаний используется в различных сферах, включая:
-
Прогнозирование связей для поиска недостающих взаимосвязей между сущностями в графах.
-
Системы рекомендаций для предложения релевантных товаров или услуг пользователям, исходя из их предпочтений и истории взаимодействий.
-
Ответы на вопросы: с помощью понимания взаимосвязей между сущностями можно создавать интеллектуальные системы для ответа на вопросы.
-
Классификация и кластеризация сущностей: использование векторных представлений для группировки схожих сущностей и категорий, что улучшает поиск и анализ данных.
Улучшение поисковых систем с помощью семантического понимания
Какие инструменты и библиотеки доступны для работы с векторными представлениями графов знаний? Для работы с векторными представлениями графов знаний доступны несколько популярных инструментов и библиотек, среди которых:
-
PyKEEN — библиотека Python, специализирующаяся на встраивании графов знаний. Она поддерживает различные алгоритмы, такие как TransE, DistMult, и ComplEx, а также предоставляет утилиты для обучения и оценки моделей.
-
AmpliGraph — еще одна библиотека Python, построенная на TensorFlow, которая подходит для создания и обучения эмбеддингов графов знаний.
-
OpenKE — фреймворк, разработанный для реализации различных алгоритмов встраивания графов знаний, таких как TransE, TransH, ComplEx и другие. Он поддерживает как C++, так и Python.
-
LibKGE — гибкий и модульный инструментарий, ориентированный на исследования и эксперименты в области встраивания графов знаний.
-
DGL-KE — высокопроизводительная библиотека, основанная на Deep Graph Library (DGL), оптимизированная для работы с крупномасштабными графами знаний.
Эти библиотеки помогают создавать и обучать модели встраивания, а также обеспечивают поддержку для работы с крупными графами.
Встраивание графов знаний в современном машинном обучении
Встраивание графов знаний преодолевает разрыв между символическими знаниями (например, фактами и взаимосвязями между сущностями) и числовыми моделями машинного обучения. Это позволяет машинам:
-
Понимать сложные структуры данных и делать на основе них обоснованные выводы.
-
Повышать точность прогнозирования, анализируя графы знаний и извлекая полезные закономерности.
-
Открывать новые возможности для приложений на базе искусственного интеллекта, таких как рекомендательные системы, интеллектуальные поисковые системы, и системы для автоматических ответов на вопросы.
Эмбеддинги помогают машине рассуждать и работать с семантическим содержимым данных, что является важным шагом к созданию более интеллектуальных и адаптивных систем.
Улучшение поисковых систем с помощью семантического понимания
Вот пример улучшения поиска с векторными представлениями графов знаний. Для более глубокого понимания того, как встраивание графов знаний может улучшить работу поисковых систем, рассмотрим пример на основе реальных данных. Предположим, что у нас есть граф знаний, представляющий продукты и их взаимосвязи с категориями, такими как электроника, мебель, бытовая техника и т.д. Задача поисковой системы — улучшить релевантность запросов и предложить пользователю более точные результаты на основе векторных представлений.
Предположим, что мы имеем такие сущности, как "Смартфон", "Ноутбук", "Телевизор", и "Пылесос", и их связи с категориями: "электроника", "мебель", "бытовая техника". С помощью векторных представлений эти элементы можно преобразовать в числовые векторы, которые будут использоваться для улучшения точности поиска.
Пример вектора:
|
Сущность |
Вектор (по осям X, Y, Z) |
|
Смартфон |
[1.2, 3.4, 0.5] |
|
Ноутбук |
[1.3, 3.5, 0.6] |
|
Телевизор |
[1.0, 3.6, 0.4] |
|
Пылесос |
[1.1, 3.0, 0.7] |
|
Электроника |
[1.4, 3.3, 0.5] |
|
Мебель |
[2.0, 3.0, 1.0] |
|
Бытовая техника |
[1.5, 3.4, 0.8] |
Эти вектора теперь могут быть использованы поисковой системой для сопоставления запроса пользователя, например, "покупка смартфона", с наиболее релевантными результатами.
Алгоритм и расчет
-
Семантическая близость: с использованием модели, такой как TransE, можно вычислить расстояние между векторами сущностей и категорий. Например, для запроса "покупка смартфона", ближайшим вектором будет "Смартфон", так как его вектор в пространстве близок к вектору категории "Электроника".
-
Предсказание релевантности: для каждой сущности система вычисляет косинусное сходство между запросом пользователя и векторами продуктов. Чем выше сходство, тем выше вероятность того, что продукт будет рекомендован пользователю.
Таблица: сходство между запросом и сущностями
|
Запрос |
Сущность |
Косинусное сходство |
|
покупка смартфона |
Смартфон |
0.98 |
|
покупка ноутбука |
Ноутбук |
0.92 |
|
покупка телевизора |
Телевизор |
0.86 |
|
покупка пылесоса |
Пылесос |
0.80 |
Как видно, модель с высокой точностью выявляет, что Смартфон имеет наибольшее сходство с запросом "покупка смартфона".
Экономический аспект внедрения
Рассмотрим экономическую сторону внедрения векторных представлений в поисковые системы и их влияние на бизнес-показатели. Использование эмбеддингов для улучшения поиска может существенно повысить конверсию и удовлетворенность клиентов.
Предположим, что компания тратит 100 000 ₽ на рекламу и привлекает 10 000 пользователей, из которых 500 делают покупку. Дает конверсию 5%.
Теперь, после внедрения улучшенного поиска с использованием векторных представлений графов знаний, точность результатов поиска увеличивается, что приводит к росту конверсии на 20%. В результате, количество покупок возрастает с 500 до 600. Дополнительный доход от увеличения конверсии:
-
Новый доход = 600 покупок × Средний чек 5 000 ₽ = 3 000 000 ₽
-
Дополнительный доход = 3 000 000 ₽ - (100 000 ₽ на рекламу) = 2 900 000 ₽
Использование векторных представлений графов знаний в поисковых системах улучшает точность поиска и повышает экономическую эффективность бизнеса, обеспечивая рост конверсии и увеличивая доход. Внедрение таких технологий может быть особенно полезным для электронной коммерции и рекомендательных систем, где каждая единица улучшения точности поиска может привести к значительным экономическим выгодам.
Проверьте, что в итоге вам понятно?
Внедрение векторных представлений для работы с графами знаний оказывает существенное влияние на бизнес-процессы, улучшая точность поиска и рекомендаций, а также повышая прибыль за счет увеличения конверсии и повышения качества обслуживания пользователей.
Многие предприниматели и владельцы сайтов, нуждающиеся в нестандартных решениях, обращаются в РОСТСАЙТ — компанию федерального уровня, которая обладает собственной нейросетью AIтут. Это дает возможность работать с данными на другом уровне, оптимизируя процессы и внедряя эффективные решения для бизнеса. Вместо стандартных решений вам предлагают гибкие инструменты, которые легко адаптируются под конкретные задачи, открывая новые горизонты для роста и развития вашего дела.
Для вас собраны бесплатные нейросетевые решения, которые можно использовать для различных рабочих задач: от создания текстов и поиска оптимальных решений до анализа данных, тестирования гипотез и автоматизации регулярных операций.
◆ ИИ-решения для бизнеса и операционной деятельности
https://aitut.ru/
◆ Нейросети для повседневных задач и их обработки
https://дипп-сик.рф
◆ Инструменты для проверки идей и сценариев реализации
https://грокнейросеть.рф
◆ Текстовые модели и решения для упрощения процессов
https://чатджпити.рф
Это практичные примеры, которые помогут оценить, насколько эти инструменты эффективны в реальной работе.
Иллюстрации созданы в РОСТСАЙТ